
Docker Swarm con AWS - Parte 2
Dovrebbe essere il 2021 dati i miei tempi biblici di pubblicazione di post in questo blog, e invece siamo ancora nel 2019 - solo perché gran parte del testo lo avevo giŕ scritto. Nella prima parte avevo parlato di una possibile infrastruttura implementativa per avere Docker Swarm con le macchine virtuali in AWS. Dopo aver creato il tutto - nodi manager e nodi worker - č ora di parlare di come fare deploy di uno o piů app. Per solo test, nel post precedente, ero entrato via SSH su una macchina virtuale, e da lě, avviato un docker container con una web app. Semplice per dimostrare la bontŕ del tutto, ma scomodissimo in un mondo dove il deploy dev'essere piů automatizzato e semplice possibile. Ipotizzo di dover aggiornare la mia web application precedente, quali passi dovrei seguire per la pubblicazione sulle mie macchine in AWS?
- Aggiornare il codice (con relativo commit che male non fa).
- Con il nuovo codice, creare una nuova immagine docker - docker build ...
- Pubblicare la nuova immagine in un private repository - docker push ...
- Entrare in una macchina manager e aggiornare - docker service update ...
Il giro č veramente noioso e troppo vulnerabile all'errore umano. L'automatizzazione del deploy dei passaggi precedenti č quanto cercherň di esporre in questo post.
Innanzitutto, AWS mette giŕ a disposizione strumenti automatici per il deploy e per il continuous delivery - Code pipeline - e infatti questo strumento si combina perfettamente con i servizi nativi come ECS. Nulla ci vieta di utilizzare Jenkins per questo compito e, effettivamente, come strumento č ben piů potente e personalizzabile del Code Pipeline anche per via dei numerosi plugin disponibili. Per due motivi usero lo strumento nativo di AWS: il primo č che l'utilizzo di Jenkins mi obbligherebbe all'installazione dello stesso su una nuova macchina virtuale con le dovute configurazioni ecc... e secondo motivo perché ho usato la scusa di questi miei test con AWS per capire quanto personalizzabile era questo strumento. Inoltre, per non dovere utilizzare piů servizi esterni, ho configurato il tutto per usare le risorse di AWS.
Nella prima parte avevo scritto pochissimo a riguardo di git in AWS: Code Commit. E' un source control basato su git con tutte le caratteristiche dell'originale, tranne che non permette l'accesso pubblico (č necessario essere loggati con una IAM role che lo permetta o la creazione di un utenza git apposita). Questo funzionalitŕ fa parte delle quattro all'interno del mondo del Code Pipeline di AWS:
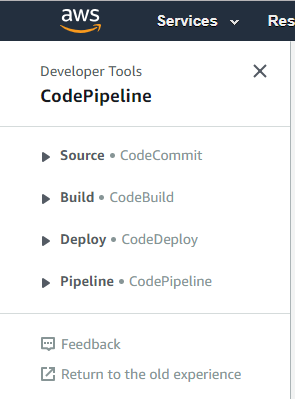
In breve: CodeBuild č il servizio per il bulding delle applicazioni, CodeDeploy per il loro deploy, e infine CodePipeline per la configurazione degli step per il deploy di una qualsiasi applicazione. Di seguito tratterň il CodeBuild e il CodePipeline; CodeDeploy, essendo troppo legato al mondo di ECS/Lambda, non č utilizzabile per i miei scopi.
Prima di andare al pratico, qualche parola su un altro servizio che utilizzerň: Amazon ECR. Questo č un private docker registry in Amazon dove č possibile inserire le proprie immagini di docker. Funziona esattamente come quello pubblico di Docker anche se ha alcune differenze: cosě come detto per il Code Commit, anche questo repository puň essere solo privato, inoltre il sistema di autenticazione non permette la classica accoppiata username e password, ma č necessario utilizzare la CLI di AWS per avere l'autenticazione valida per dodici ore.
Ne ho parlato anche nel post precedente su questo sistema di autenticazione di AWS. Appare scomodo, e lo č pure nell'uso - di seguito, per la gestione del repository docker privato mostrerň un accorgimento ad hoc per il suo uso - ma questo innalza il livello di sicurezza. Nel caso di Git, possiamo, da qualsiasi risorsa all'interno di AWS, avere l'autenticazione immediata con questi comandi da terminale:
git config --system credential.helper '!aws codecommit credential-helper $@' git config --system credential.UseHttpPath true
Per usare questa feature č necessario che la risorsa che la utilizza abbia la IAM role abilitata per questo - rimando ancora al post precedente. Ma č possibile avere anche le tipiche credenziali con username e password per poter usare Git anche al di fuori da AWS - ripeto, dalle risorse di AWS č preferibile usare, se č possibile, l'approccio precedente. Per fare questo č sufficiente, per qualsiasi l'utente abilitato in AWS per la gestione di Git e del repository, andare nel Security credentials per quell'utente e, nella sezione HTTPS Git credentials for AWS CodeCommit generare le credenziali:

Con il private repository per Docker la cosa č differente: non č possibile creare credenziali da utilizzare poi per l'antenticazione e il download delle nostre immagini. Per fare questo č necessario autenticarsi con la CLI di AWS. Innanzitutto č necessario scaricare e installarsi questa CLI. Quindi da terminale (versione scorciatoia):
$(aws ecr get-login --no-include-email --region eu-central-1)
Eseguito, l'autenticazione sarŕ valida per 12 ore e si potranno usare i vari comandi cosě come si usano con qualsiasi altro repository. Naturalmente, la CLI di AWS č eseguita con un determinato utente al quale dev'essere assegnato la policy AmazonEC2ContainerRegistryPowerUser (con la possibilitŕ di dare ovviamente i permessi ai soli repository necessari).
E ora di mettere tutto in pratica per poi affrontare i vari problemi che si presenteranno. La prima fase č creare una web application, ma stando piů sul semplice, tale applicazione presenterŕ solo l'interfaccia API REST con il classico endpoint values, nel mio caso userň quella di esempio per asp net Core 2.2:
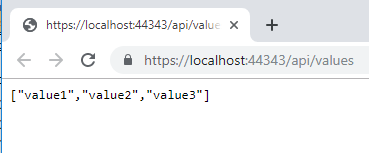
Il cui codice presenta solo la modifica per l'aggiunta del terzo valore:
public ActionResult<IEnumerable<string>> Get()
{
return new string[] { "value1", "value2", "value3" };
}Non poteva mancare il codice per testare che tutto funzioni correttamente. Alla soluzione ho aggiunto un progetto xUnit Test per la verifica con due semplici Unit test che il tutto funzioni correttamente:
using AzDotnetExample1.Controllers;
using FluentAssertions;
using Microsoft.AspNetCore.Mvc;
using System;
using System.Collections.Generic;
using System.Linq;
using Xunit;
namespace XUnitTestProject1
{
public class UnitTest1
{
[Fact]
public void TestReturnType()
{
var controller = new ValuesController();
var result = controller.Get();
var okResult = result.Should().BeOfType<ActionResult<IEnumerable<string>>>().Subject;
}
[Fact]
public void TestReturnValues()
{
var controller = new ValuesController();
var result = controller.Get();
var okResult = result.Should().BeOfType<ActionResult<IEnumerable<string>>>().Subject;
var persons = okResult.Value.Should().BeAssignableTo<IEnumerable<string>>().Subject;
persons.Count().Should().Be(3);
persons.Should().Contain("value1");
persons.Should().Contain("value2");
persons.Should().Contain("value3");
}
}
}Inserito il tutto in Git di AWS si č pronti ad utilizzare la Code Pipeline. Sě, perché č ora di mettere tutto insieme. Nel post precedente avevo creato le mie macchine per gestire i container nello Swarm di Docker, e ora č arrivato il momento far interfacciare la Code Pipeline con la nostra struttura. Da interfaccia di AWS:
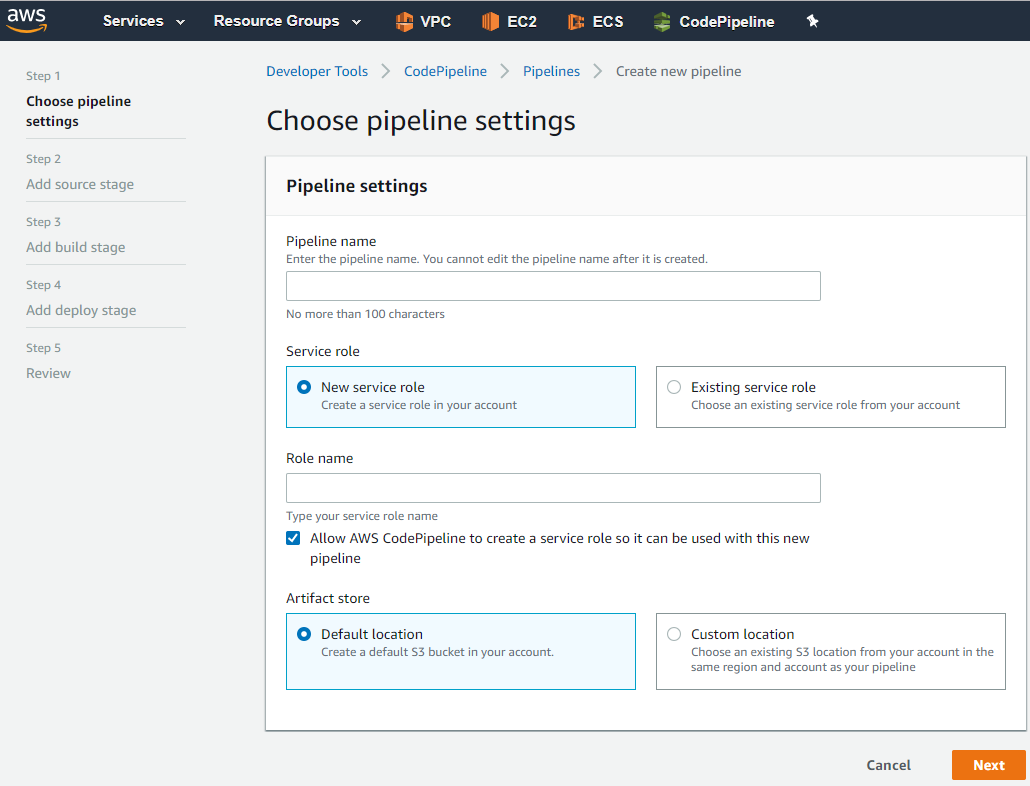
Inserito il nome possiamo lasciare che sia lui a creare una service role di base (che poi si potrŕ modificare per particolari esigenze). Inoltre si potrŕ specificare dove salvare gli artifact - questi non sono altro che il risultato che ogni stage della pipeline puň passare allo stage successivo, nel caso di AWS, questi vengono salvati in un bucket in S3 che possiamo fare in modo che nei crei uno lui con il suo nome casuale o possiamo utilizzarne uno giŕ creato (questo č ottimo per mantenere un certo ordine nel bucket di S3 e per creare eventualmente una lambda che, schedulata, vada a ripulire e rilasciare risorse inutili per esecuzione della pipeline piů vecchie).
Passo successivo, source del nostro progetto:
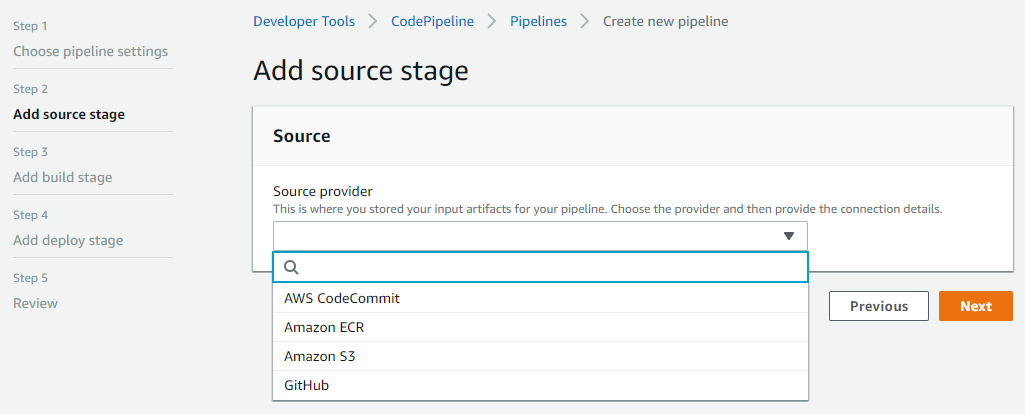
AWS CodeCommit č il git interno di AWS (come ho giŕ scritto piů volte e che utilizzerň), AMAZON ECR č il private repository docker di AWS, con Amazon S3 si puň scegliere il bucket e il nome dell'oggetto dov'č il codice, GitHub č il repository ufficiale di Git. In quest'ultimo caso, selezionandolo, potremo inserire le informazioni utili per la connessione il webhook per fare in modo che, in caso di aggiornamento del codice in git, questo possa avviare automaticamente la pipeline di AWS:

Nel mio caso selezionerň il CodeCommit di AWS:

In Change detection options selezionando la prima voce, la pipeline sarŕ avviata ad ogni commit del codice (con la seconda il controllo sarŕ schedulato in modo che verifichi l'aggiornamento di codice, anche se non ho mai trovato l'utilitŕ di una simile scelta avendo la prima).
Passo successivo. Ora la pipeline ha il nostro codice ed č ora di elaborarlo. Ora si deve, anzi, per essere corretto, si puň definire il passo per il build del codice:

Questo punto č interessante, perché si puň selezionare la CodeBuild di AWS oppure richiamare un'installazione di Jenkins sia interna ad AWS che esterna. Nel mio caso userň CodeBuild:

Si puň selezionare un CodeBuild giŕ esistente o creane uno nuovo, cliccando su Create project:
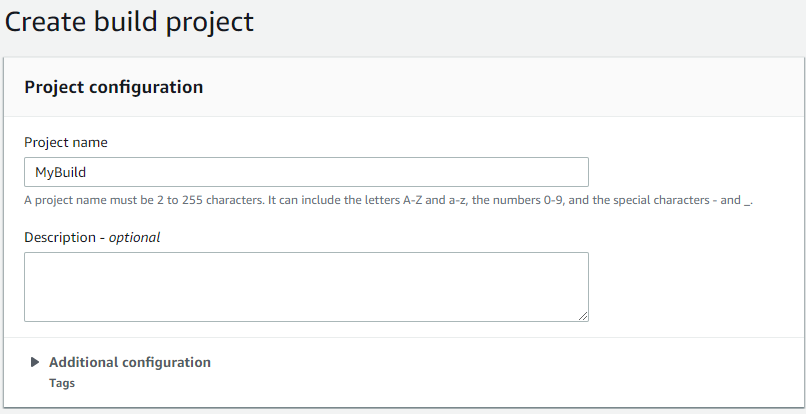
Specificato il nome ed un'eventuale descrizione, si deve selezionare l'immagine che sarŕ utilizzata per la build del codice. Immagine? Sě, perché AWS usa un'immagine preconfezionata di Docker:
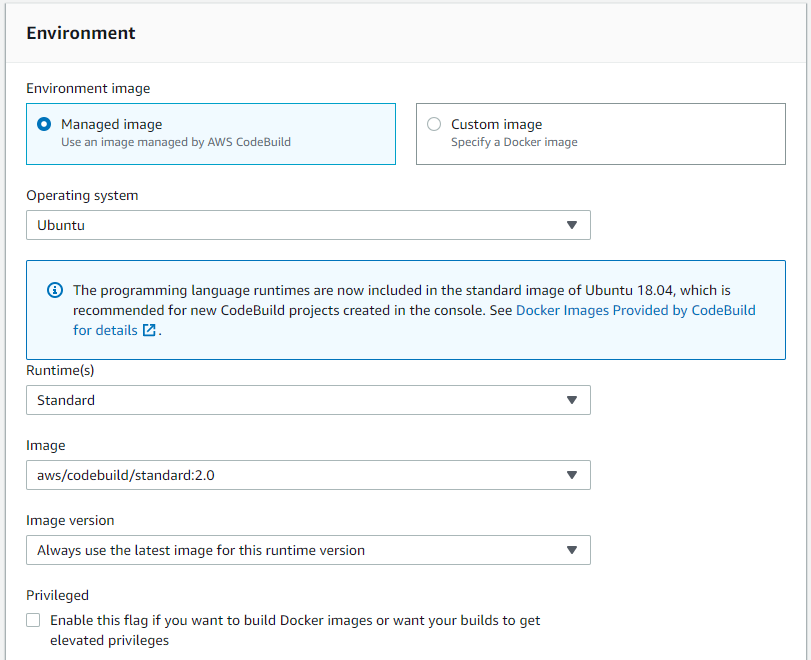
Nella versione attuale della Code Build č presenta una immagine con i principali linguaggi:
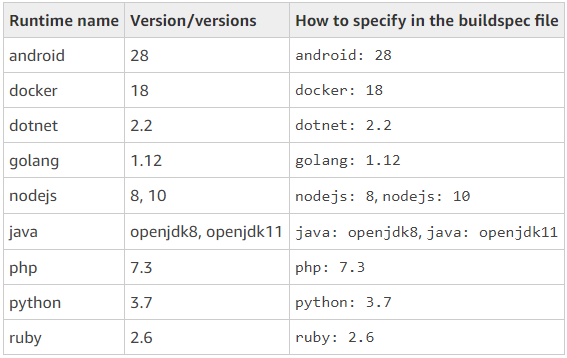
Inoltre č possibile aumentare i privilegi in caso si debba creare una nuova immagine di Docker - come nel mio caso. Ritornando al discorso delle tecnologie o linguaggi utilizzati, nella versione precedente c'era un'immagine per ogni tecnologia:

L'avere tutto in un'unica immagine ha finalmente risolto un problema che la pipeline di AWS si portava dietro da sempre. Se per la build del mio progetto avessi avuto bisogno di piů tecnologie, avrei avuto tre possibili soluzioni: creare una Code Build per il primo linguaggio di programmazione, quindi, creare uno step successivo con una nuova Code Build per il secondo linguaggio di programmazione, e cosě via; qual era il problema di questo scenario? La velocitŕ: l'avvio di un'immagine Docker nella pipeline di AWS č una procedura lenta (su questo fronte perde completamente se confrontato con Jenkins), se poi si creano una moltitudine di step per la Code Build, la build e il deploy finale del progetto diventava veramente lento. Seconda scelta era usare un'immagine di base e installare quanto serve; come soluzione funziona, ma il download e l'installazione di tutti gli strumenti che ci potrebbero servire rallenta ancora maggiormente la build - si puň immagine che cosa voglia dire installare .net Core e Docker per ogni modifica nel codice. Altra scelta č creare un'immagine con giŕ tutto il necessario: compilatore .NET Core e Docker e tutto quello che ci puň servire; questa č la soluzione piů performante anche se di contro il problema che la manutenzione, aggiornamento e altro rimane compito nostro (nulla di preoccupante alla fine). Tale scelta č obbligatoria anche nel caso di versioni non ancora aggiornate in AWS ma disponibili; per esempio, se si volesse usare .Net Core 3.0 (in RC nel momento della scrittura di questo post) quest'ultima scelta č l'unica performante; quest'ultima scelta č inoltre insostituibile quando ci si scontra con l'assenza di tutti gli strumenti necessari per il deploy del nostro progetto.
Ritornando al mio progetto, ho il codice sorgente disponibile e ora lo devo compilare, lanciare gli unit test per controllare che il codice committato non abbia problemi (come se bastassero solo quei test per verificarlo!) e da questo codice devo creare un'immagine Docker con tutto il necessario. Inizio inserendo il nome per questa Code Build, seleziono l'ultima immagine disponibile (aws/codebuild/standard:2.0), inserisco il check per i privilegi e ci troviamo di fronte due punti importantissimi: l'inserimento del codice per tutte le operazioni dette prima e la service role che ci permetta di fare tutto questo. Inizio parlando dove si specifica la compilazione del codice. Questo viene fatto con uno script apposito che possiamo inserire direttamente nel codice sorgente, oppure all'interno di questa pagina:

Con la prima opzione č possibile inserire tale file direttamente nel codice sorgente (di default con il nome buildspec.yml ma č modificabile), mentre con la seconda opzione č possibile inserirlo direttamente qui:
version: 0.2
run-as: Linux-user-name
env:
variables:
key: "value"
key: "value"
parameter-store:
key: "value"
key: "value"
phases:
install:
run-as: Linux-user-name
runtime-versions:
runtime: version
runtime: version
commands:
- command
- command
finally:
- command
- command
pre_build:
run-as: Linux-user-name
commands:
- command
- command
finally:
- command
- command
build:
run-as: Linux-user-name
commands:
- command
- command
finally:
- command
- command
post_build:
run-as: Linux-user-name
commands:
- command
- command
finally:
- command
- command
artifacts:
files:
- location
- location
name: artifact-name
discard-paths: yes
base-directory: location
secondary-artifacts:
artifactIdentifier:
files:
- location
- location
name: secondary-artifact-name
discard-paths: yes
base-directory: location
artifactIdentifier:
files:
- location
- location
discard-paths: yes
base-directory: location
cache:
paths:
- path
- pathNella sezione env possiamo importare le variabili da passare poi al codice (variabili su cui si puň fare override da interfaccia, questa feature č molto interessante e da approfondire se si pensa di far uso della code pipeline di AWS, inoltre sono passate altre variabili che potrebbero essere utili - non approfondisco, ma molte info si possono trovare qui), quindi ci sono le varie fasi di build, e gli artifact. Questi ultimi sono utilizzabili per definire quali file, giŕ presenti o creati, vogliamo siamo passati eventualmente ad un nuovo step della pipeline; ulteriori informazioni si possono trovare qui. Attenzione alle varie sezioni pre_build, build e post_build: esse vengono eseguite anche se le operazioni nella sezione precedente hanno dato errore. Ipotizzando di aver inserito nella sezione build lo script per la compilazione e nello sezione post_build lo script per creare l'immagine Docker, quest'ultimo passaggio sarŕ eseguito ugualmente anche se la compilazione ha dato errori - queste sezioni sono da utilizzare per preparare o liberare le risorse prima e dopo il loro uso, per esempio.
Questo č lo script che ho utilizzato per la compilazione, il test del codice, la creazione dell'immagine Docker e il suo invio nel mio repository privato:
version: 0.2
phases:
install:
runtime-versions:
dotnet: 2.2
docker: 18
build:
commands:
- dotnet restore
- dotnet build -c release
- dotnet test XUnitTestProject1
- echo Logging in to Amazon ECR...
- cd AzDotnetExample1
- $(aws ecr get-login --no-include-email --region eu-central-1)
- ls -R .
- echo Build started on `date`
- echo Building the Docker image...
- docker build -t sbraer:latest .
- docker tag sbraer:latest 838080890745.dkr.ecr.eu-central-1.amazonaws.com/sbraer:latest
- echo Build completed on `date`
- echo Pushing the Docker image...
- docker push 838080890745.dkr.ecr.eu-central-1.amazonaws.com/sbraer:latest
artifacts:
files:
- startDocker.sh
name: docker
discard-paths: yes
base-directory: AzDotnetExample1In runtime-verions ho inserito, come ben specificato dalla documentazione, le due tecnologie di cui avevo bisogno - dotnet e docker. Quindi nella sezione build tutti i comandi dello script per la compilazione piů messaggi utili, nel mio caso, per verificare i vari passaggi che saranno inseriti nel log. Nella sezione artifacts, ho specificato quale file sarŕ trasportato negli step successivi (startDocker.sh č un semplice script bash) di cui parlerň in seguito.
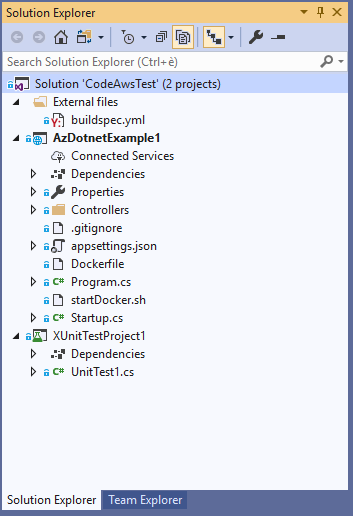
E' ora di vedere la struttura del mio progetto:
Durante l'esecuzione di questo step nella pipeline, sarŕ possibile vedere l'output di questo script nel link apposito, su cui si potrŕ vedere il dettaglio di quello che sta succedendo, per esempio:
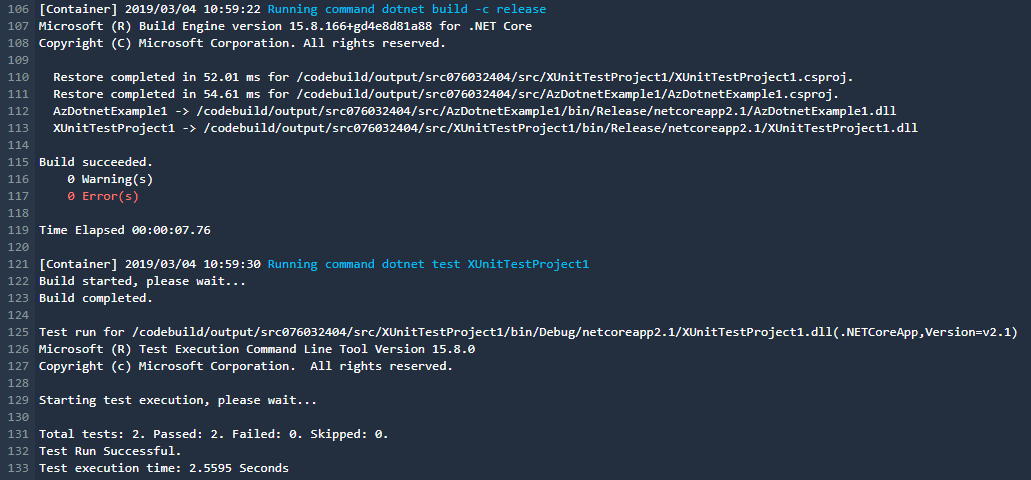
Nella struttura del progetto sopra, si puň vedere come ho inserito il file buildspec.yml all'interno del progetto, in modo che CodeBuild di AWS lo usi direttamente (lui cerca quel file all'interno della root del progetto scaricato).
Infine, AWS č un grado di creare per noi la service role adatta per la build:
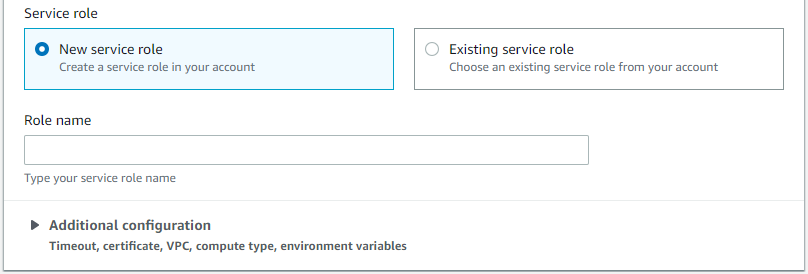
O posso crearla io e inserirla qui come parametro. Attenzione, lui non controlla nulla nel codice per la sua creazione: ogni volta crea una standard che dovrebbe andare bene nella maggior parte dei casi, ma se dovessi accedere a qualche risorsa in particolare sarei obbligato a metterci mano, come farň tra breve.
Infine, essendo che il mio script produce un artifact, č bene specificarne il nome:

E' il momento di avviare il tutto, ma al momento della login in Docker ottengo l'errore:
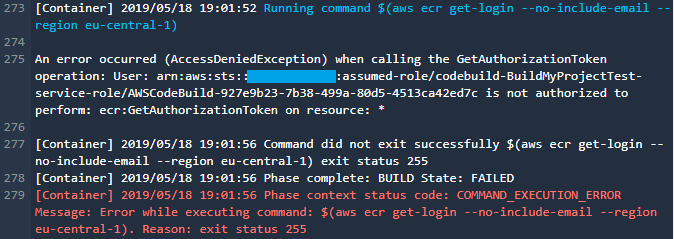
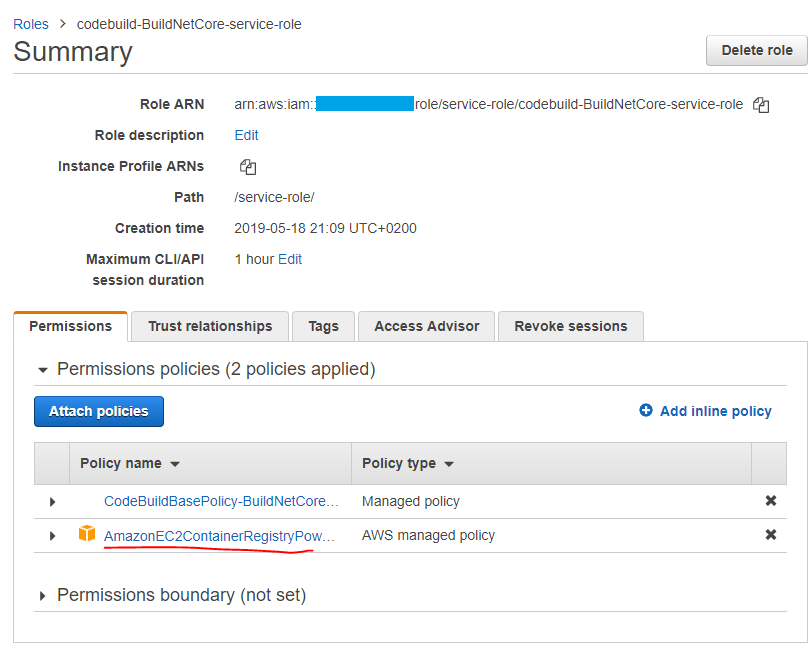
L'errore alla riga 275 specifica che il mio script non ha le autorizzazioni per la login nel mio repository privato di Docker. Per risolvere il problema č sufficiente andare nella role utilizzata dalla mia Code Build:
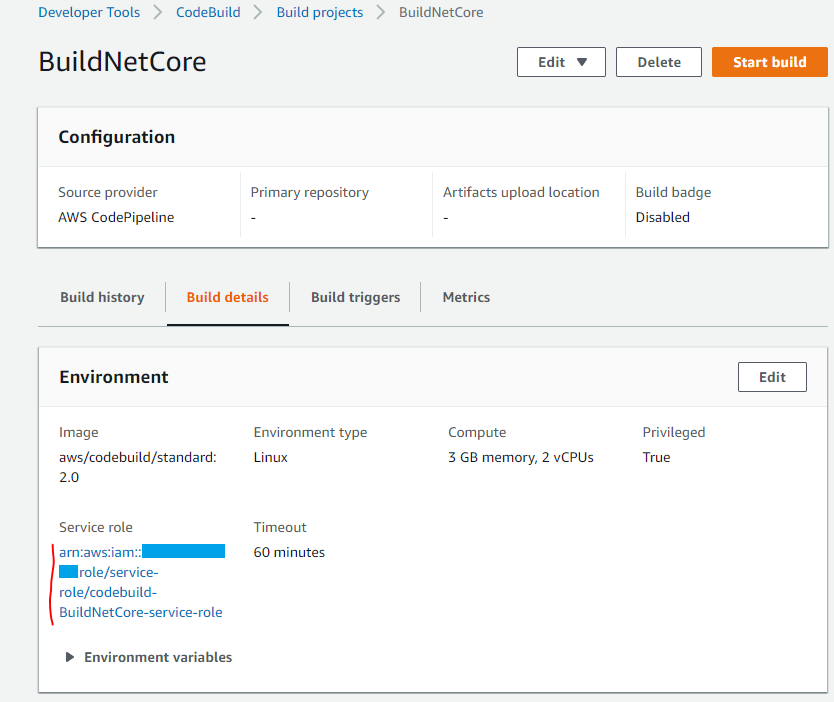
Cliccando sulla service role, č sufficiente aggiungere la policy AmazonEC2ContainerRegistryPowerUser:
Al riavvio della pipeline, il codice sarŕ compilato, l'immagine Docker creata e inviata al repository:
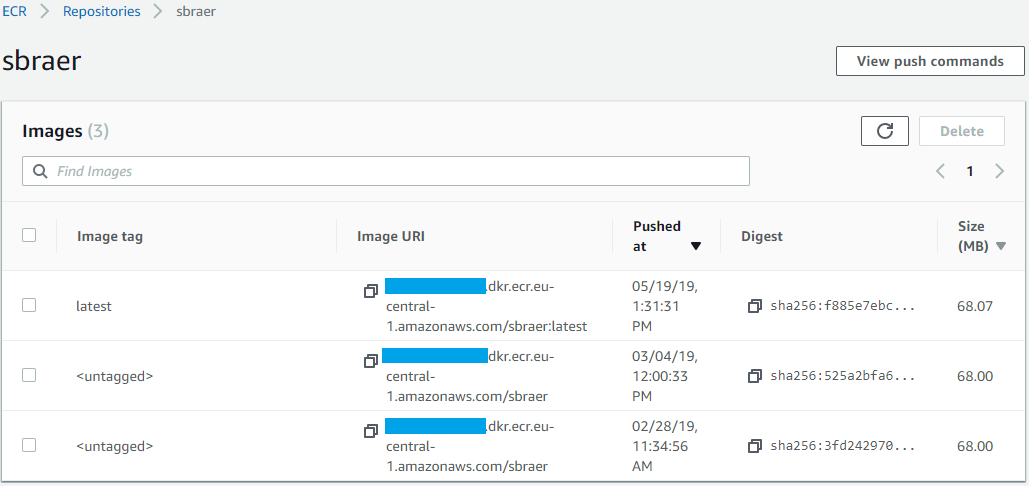
Nell'immagine qui sopra si possono vedere piů immagini perché frutto di alcuni miei test giŕ fatti su questo progetto. Aggiungo solo come informazioni da ricordare che č possibile definire una regola per la cancellazione delle immagini piů vecchie in modo da non occupare spazio prezioso (non solo per la quantitŕ ma anche per il costo).
Per controllo posso verificare che cosa č stato inserito come artifact in S3 come output del mio script. In AWS vado su S3, mi trovo il bucket codepipeline-eu-central-1-777870911640 e all'interno la directory MyTest (che č il nome della mia pipeline): sono nel posto giusto, e qui trovo il file con il nome che avevo specificato prima - BuildNet22:
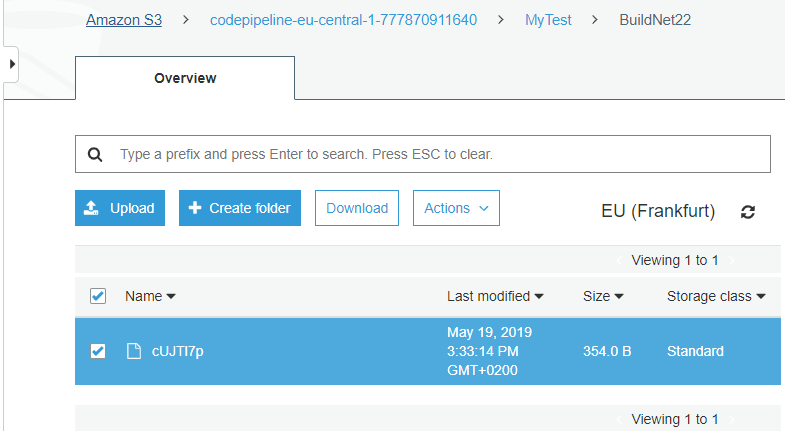
E' possibile scaricarlo, č mi troverei con un file zip contenente il file (o piů file), nel mio caso l'unico file startDocker.sh. Questo file contiene il file bash che comunicherŕ alla mia rete Docker Swarm specificata nel mio post precedente quello che deve fare.
Proseguendo nella pipeline, mi sarŕ chiesto di creare lo step per il code deploy, non potendo usare questo passo della pipeline la salto cliccando sul pulsante skip e salvo la pipeline. Ora riapro la pipeline in modalitŕ edit e aggiungo un nuovo Stage in cui inserisco un nuovo Code Build subito dopo a quello appena creato. E qui inizia la parte interessante. Quanto visto finora non si discosta molto da quanto si puň trovare ben documentato. Ora devo comunicare alla mia rete Docker Swarm che un'applicazione .Net Core č pronta e dev'essere avviata:
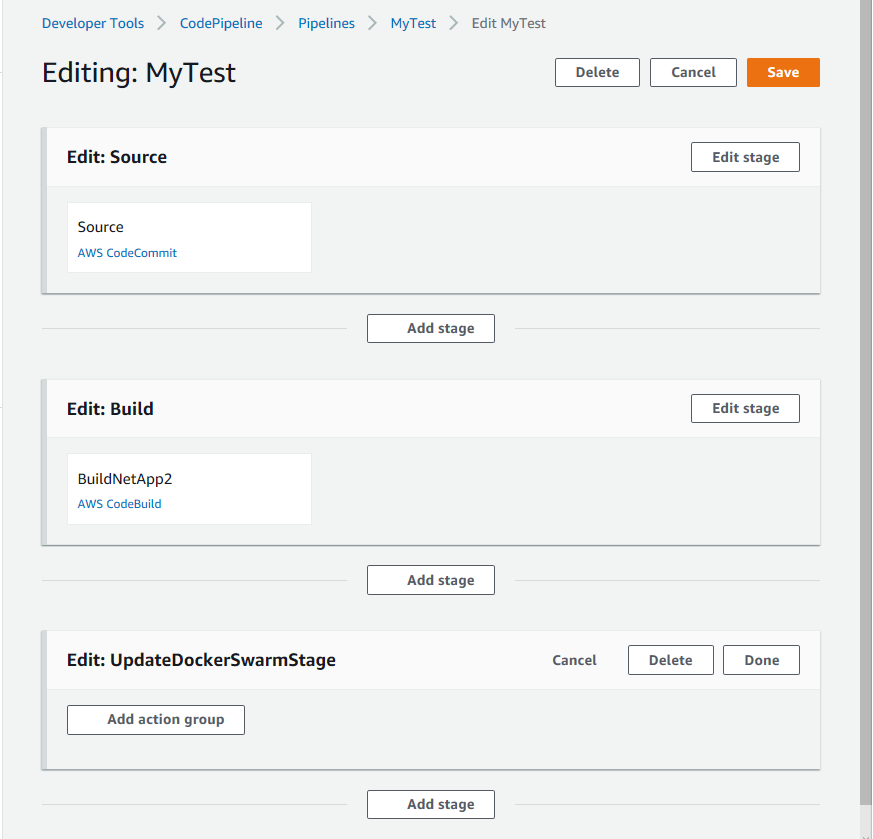
Creato il nuovo Action group e selezionato il code build come da immagine:
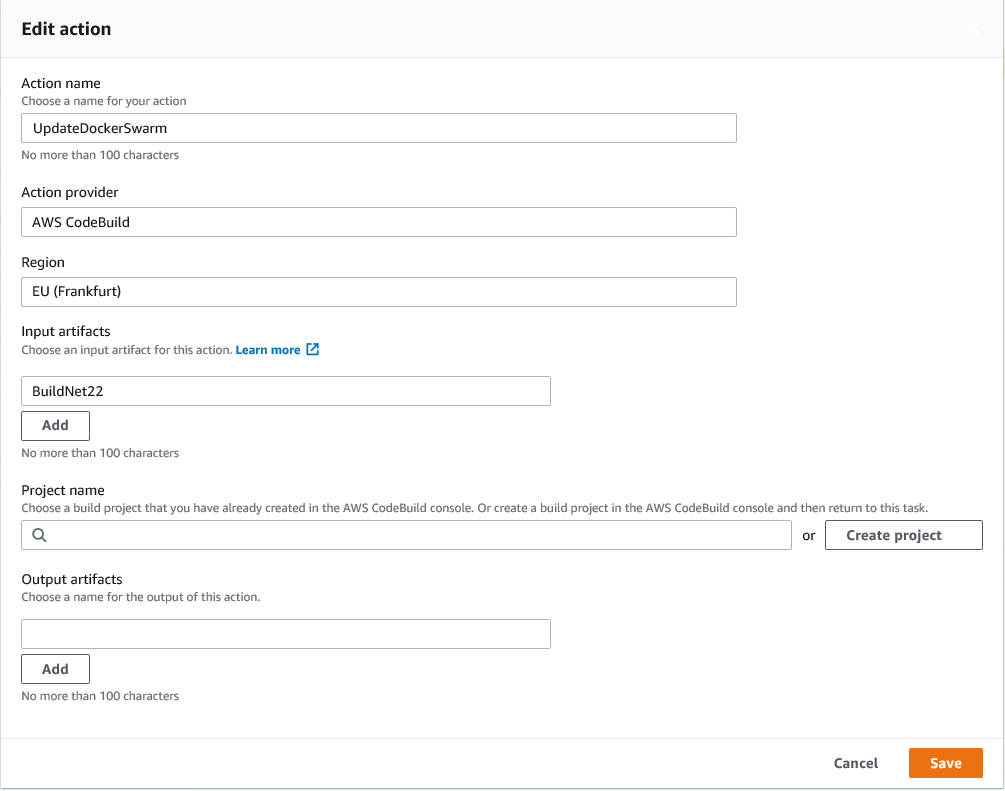
Importante la selezione dell'artifact dallo stage precedente (ricordo, č il file bash visto in precedenza). Quindi creo il nuovo project, come fatto prima, ma in questo caso devo andare in Addiotional Configuration per aggiungere alcune impostazioni:

Ho definito la VPC da utilizzare con le sue subnet e il security group. Questo perché dai miei script devo accedere alle risorse che girano all'interno della mia VPC e sulle mie macchine virtuali. L'immagine Docker che gira nella pipeline č indipendente da tutto, senza queste impostazioni NON potrebbe mai raggiungere degli IP di questa rete (192.168.0.250 etc...). Altra personalizzazione č il codice da eseguire (inserito manualmente invece di usare il file buildspec.yml):
version: 0.2
phases:
install:
runtime-versions:
nodejs: 10
build:
commands:
- ls -R .
- chmod +x startDocker.sh
- ./startDocker.shIl comando ls č solo per mostrare nel log il contenuto dei file passati (č per un mio check), quindi imposto il flag per rendere eseguibile il file preso dalla build precedente, e lo eseguo.
Il suo contenuto č il seguente:
#!/bin/bash
curl -f -X PUT -H "Content-Type: application/json" -d '{"servicename":"app0","image":"sbraer/aspnetcorelinux:api1","portdocker":"5000","portmachine":"5000","region":"eu-central-1"}' http://192.168.0.250:64000/api/dockerswarm/service
if [ $? -eq 0 ]; then
exit 0
fi
curl -f -X PUT -H "Content-Type: application/json" -d '{"servicename":"app0","image":"sbraer/aspnetcorelinux:api1","portdocker":"5000","portmachine":"5000","region":"eu-central-1"}' http://192.168.16.250:64000/api/dockerswarm/service
if [ $? -eq 0 ]; then
exit 0
fi
curl -f -X PUT -H "Content-Type: application/json" -d '{"servicename":"app0","image":"sbraer/aspnetcorelinux:api1","portdocker":"5000","portmachine":"5000","region":"eu-central-1"}' http://192.168.32.250:64000/api/dockerswarm/service
if [ $? -eq 0 ]; then
exit 0
fiUno alla volta richiamata con curl una API Rest sulle tre macchine manager (viste nel post precedente) utilizzando come parametro il nome del service name usato in Docker, l'immagine da utilizzare (sia per una nuova istanza sia nel caso di un aggiornamento), le porte da mappare e la region in AWS da usare. Riprendendo il repository sempre da quel post, sarŕ eseguito questo codice (in nodejs):
app.put("/api/dockerswarm/service", (req, res) => {
const { servicename, image, portdocker, portmachine, region } = req.body;
if (!servicename || /^([a-zA-Z0-9]{1,50})$/.test(servicename) === false) {
res.status(400).send({ message: 'invalid servicename supplied' });
}
else if (!image || image.length > 250) {
res.status(400).send({ message: 'invalid image supplied' });
}
else if (!isFinite(portdocker)) {
res.status(400).send({ message: 'invalid portdocker supplied 1024-65535' });
}
else if (!isFinite(portmachine)) {
res.status(400).send({ message: 'invalid portmachine supplied 1024-65535' });
}
else if (!region || region.length > 50) {
res.status(400).send({ message: 'invalid region supplied' });
}
else {
const dockerCommand = `sh ./update_service.sh "${servicename}" "${image}" "${portdocker}" "${portmachine}" "${region}"`;
execFunction(dockerCommand, res, false);
}
});I parametri passati precedentemente vengono letti da questa riga:
const { servicename, image, portdocker, portmachine, region } = req.body;Dopo alcuni controlli viene eseguito un altro bash file con questi parametri:
#!/bin/bash
SERVICENAME=$1
IMAGEDOCKER=$2
PORTDOCKER=$3
PORTMACHINE=$4
REGION=$5
# Check parameters
if [ -z "$SERVICENAME" ]; then
exit 1
fi
if [ -z "$IMAGEDOCKER" ]; then
exit 1
fi
if [ -z "$PORTDOCKER" ]; then
exit 1
fi
if [ -z "$PORTMACHINE" ]; then
exit 1
fi
if [ -z "$REGION" ]; then
exit 1
fi
# login into AWS docker repository
eval $(aws ecr get-login --region $REGION --no-include-email)
if [ ! $? -eq 0 ]; then
exit 2
fi
# Check if service is already installed/running
docker service ps $SERVICENAME
if [ $? -eq 0 ]; then
# echo OK
docker service update --with-registry-auth --force --update-parallelism 1 --update-delay 30s $SERVICENAME # update service
else
# echo FAIL
docker service create --network mynet --with-registry-auth --name $SERVICENAME -p $PORTMACHINE:$PORTDOCKER $IMAGEDOCKER # install service
fiAnche qui vengono letti i parametri, eseguiti dei banali controlli, quindi viene eseguita la login nel repository privato di AWS con il metodo giŕ spiegato, infine se il servizio č giŕ avviato viene fatto un update altrimenti viene creato.
Finito. Salvo il tutto ed ecco la pipeline appena creata:
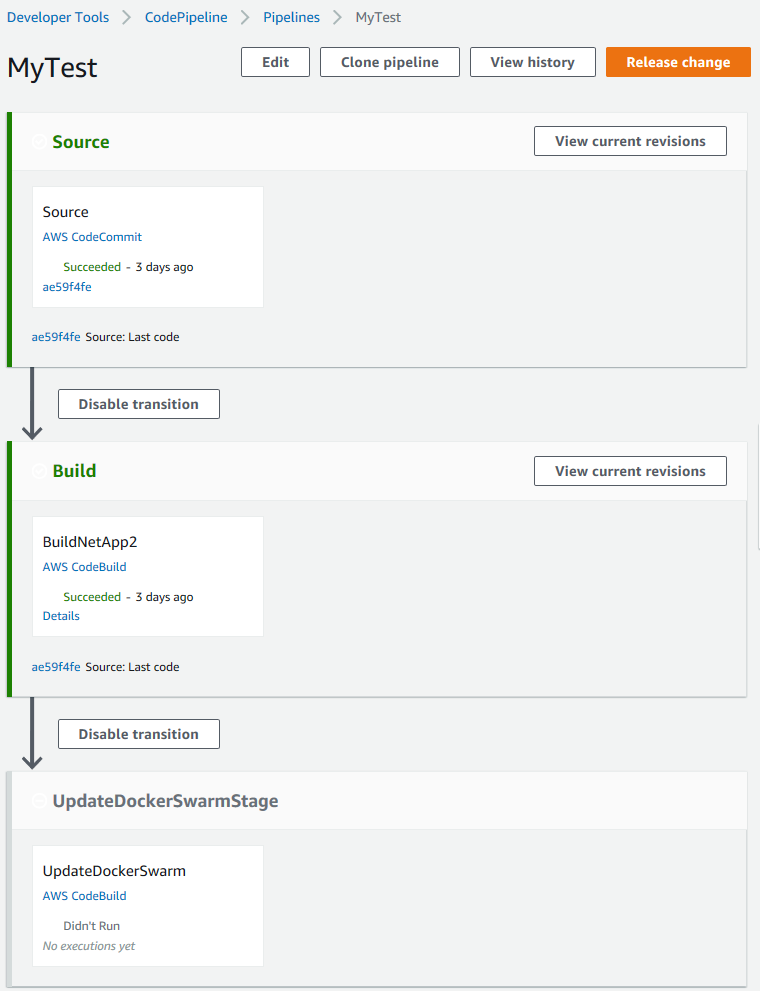
Due modi per avviarla: modifico il codice sorgente oppure un click sul button "Release change" (nell'immagine i primi due stage sono giŕ verdi perché da me giŕ testati precedentemente). Per ogni singola stage in esecuzione č sufficiente cliccare sul link Details per vedere passo passo cosa sta accadendo. L'esecuzione dei miei due stage viene eseguita in poco tempo senza problemi, ma il terzo stage ha un comportamento strano, sembra non venga eseguito:
Dopo qualche minuto vedo l'errore:
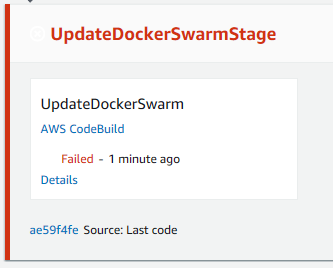
L'errore non sarŕ visibile nel log vista prima ma solo in Phase details:
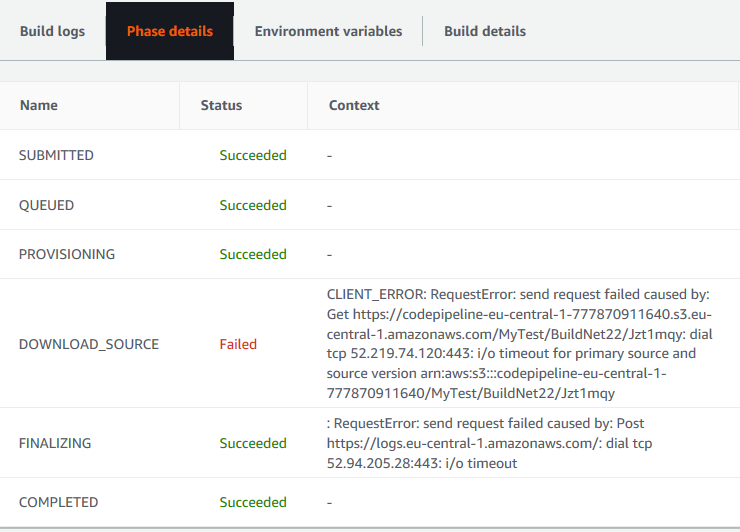
Qualcosa č andato storto quando lo stage ha cercato di accedere a S3. Senza tirarla per le lunghe, il problema alla configurazione di questo stage all'interno della mia VPC come se questo girasse effettivamente come un processo nella mia rete e da quella posizione NON puň accedere direttamente a S3 e nemmeno al servizio dei log (per questo non si vedono righe nella pagina dei dettagli). Per risolvere il problema č necessario aprire un Endpoint nella mia VPC che permetta di accedere a S3:
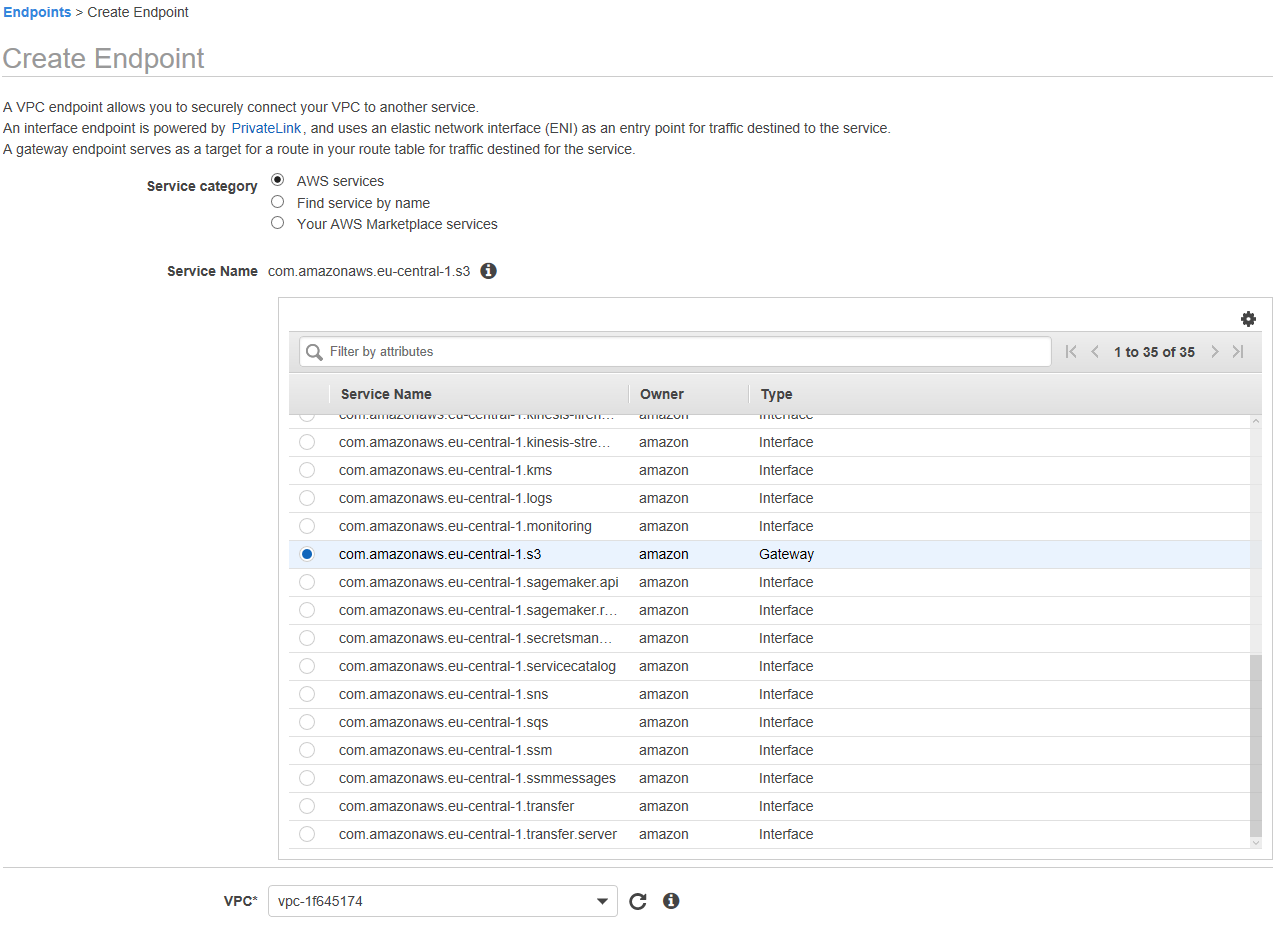
Ci sono due tipi di Endpoint: Interface e Gateway. La differenza? I primi si pagano. Per mia fortuna io utilizzo l'endpoint per S3 che č un gateway (come si vede nell'immagine precedente). Selezionata questa opzione e la mia VPC, seleziono anche la mia Route table ed eventualmente una policy personalizzata (lascio per comoditŕ quella di default che permette l'accesso a tutti i bucket anche se sarebbe da evitare, ovviamente):
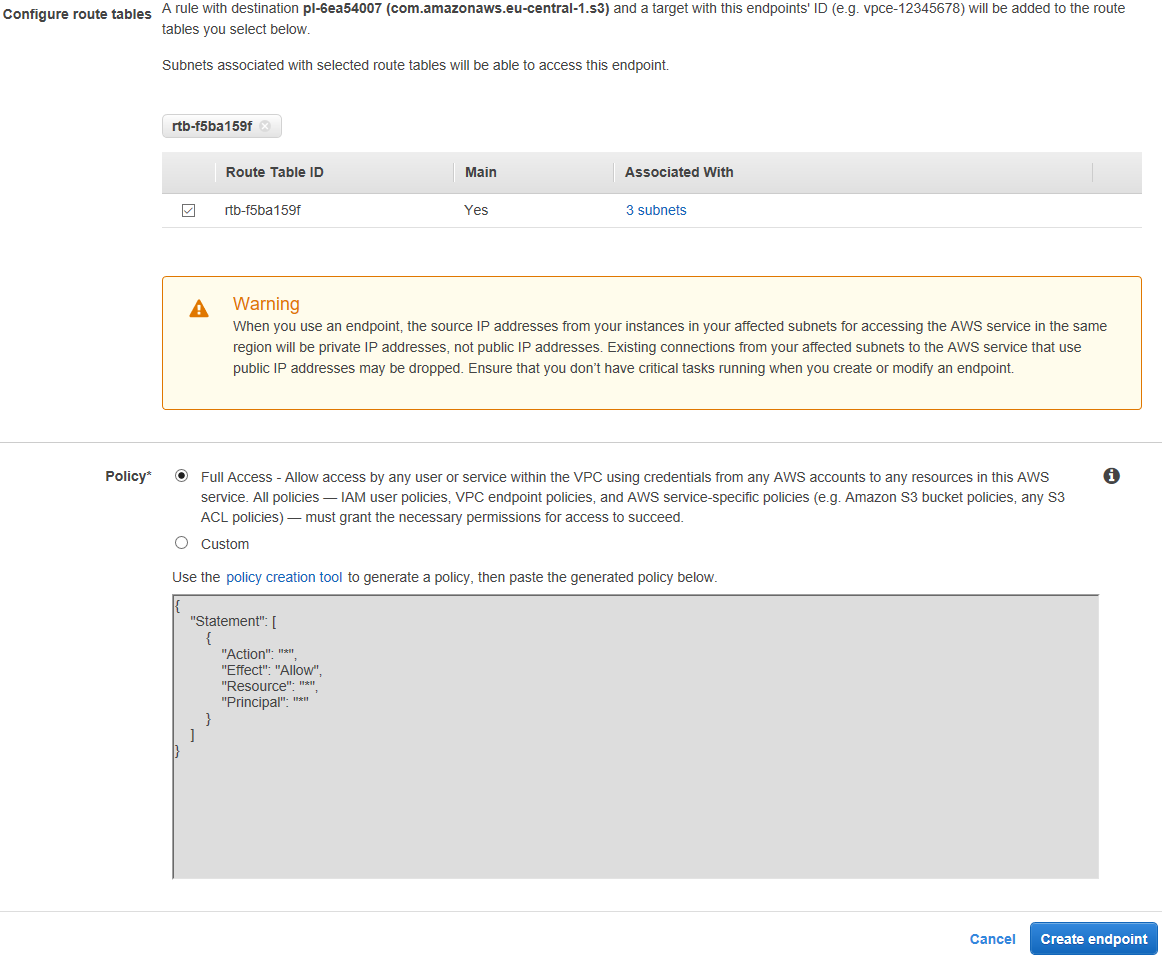
Questo non permetterŕ l'aggiornamento corretto del log come scritto prima, per abilitare anche quello č necessario abilitare un Endpoint Interface, che si paga - nel dettaglio sarŕ necessario abilitare l'endpoint com.amazonaws.eu-central-1.events.
Ok, creo l'Endpoint (maggiori informazioni sugli Endpoint, qui) e verifico che funzioni tutto:
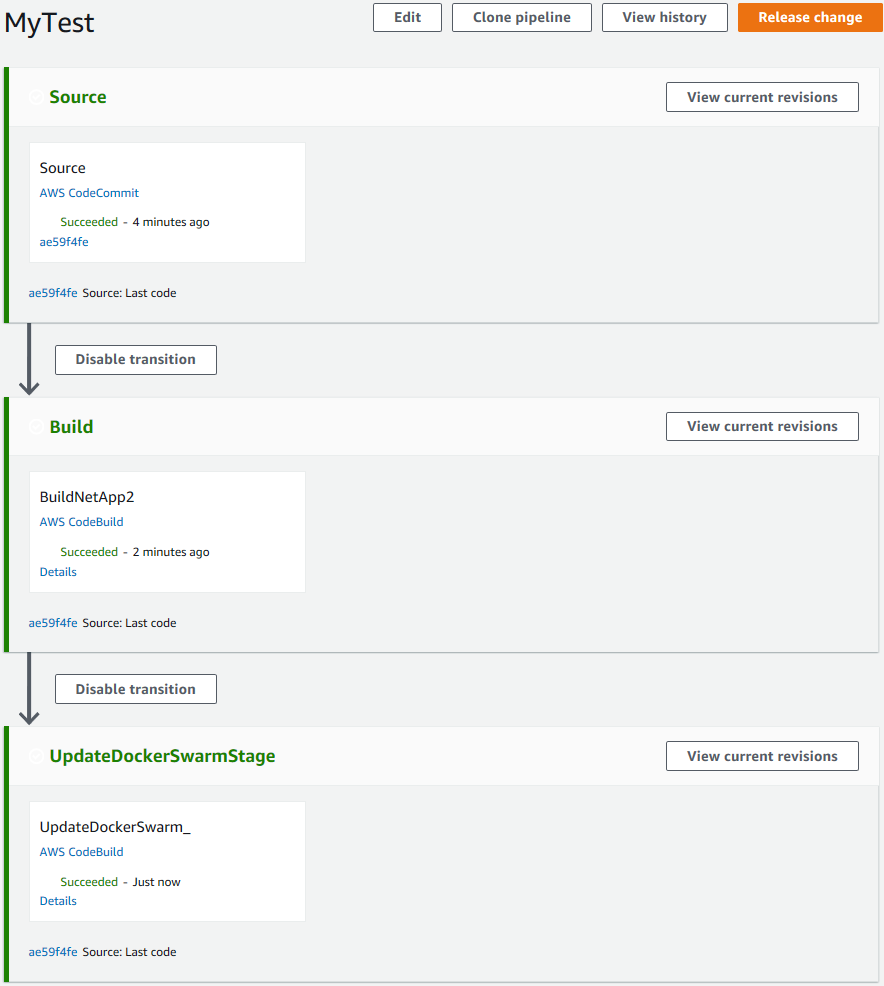
E controllando nella mia rete controllo che la web app si č aggiornata correttamente.
La personalizzazione in Code Build permette anche altri trucchi molto utili. Per esempio, per le stringhe di connessione contenenti password o altro che č meglio tenere lontano da occhi indiscreti, possiamo fare in modo che queste credenziali, preventivamente inserite nel Secret Manager di AWS, possano essere iniettate all'interno del container o alla macchina virtuale. Un'altra opzione piů sicura č inserire direttamente nell'applicazione la possibilitŕ di leggere direttamente queste credenziali da Secret Manager. Personalmente preferisco questa opzione: a livello di codice il tutto si basa nello scrivere una funzione che vada a prendere il valore voluto direttamente - purtroppo non ho trovato altri automatismi. Di questo problema soffrono anche altri servizi utili in AWS. Per l'esempio, l'X-Ray utile per tracciare le richieste tra i vari servizi, puň essere incluso nei progetti .Net solo modificando il codice come spiegato qui; se in qualche passaggio la modifica č semplice, in altre si deve mettere mano e modificare le parti del nostro codice che, per esempio, fanno richieste esterne ad AWS.
E' ora di tirare le conclusioni. Aws metta giŕ a disposizione strumenti giŕ belli pronti per fare tutto - ECS con Fargate o meno, Elastic Beanstalk, OpsWorks etc... - e avrei avuto molti meno problemi utilizzandoli visto che sono nativi e ben documentati. Ma con questi post ho solo voluto mostrare come si puň customizzare il po' il tutto scoprendo altre cose interessanti. Purtroppo gli argomenti trattati sono molti, ed ho potuto solo accennarli. Si vuole approfondire? La documentazione di AWS č abbastanza completa. E la chiudo qui. In questi due post non si č capito niente? Ho i miei limiti.

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
- AWS Lambda Custom Rutime in C++, il 18 giugno 2022 alle 09:52
- AWS Lambda Cold Start in C# e..., l'11 giugno 2022 alle 12:28
- AWS e Docker Cloudstor, il 10 novembre 2019 alle 13:55
- Docker Swarm con AWS - Parte 1, il 24 aprile 2019 alle 15:30