
Docker Swarm con AWS - Parte 1
Sono passati due anni dal mio ultimo post riguardante il mondo Docker e forse ora di scrivere qualcosa d'altro su questa tecnologia anche perché questo mi consente di tenere memoria di quanto fatto. Alla prima stesura di questo post mi sono reso conto che era troppo il materiale da esporre e spiegare, quindi ho eseguito numerosi tagli e diviso in due differenti post quanto scritto. Inoltre quanto qui esposto non č adatto a chi non sa nulla di Docker con AWS, quindi qualsiasi critica "Ma non si capisce niente!" o confronti con altri servizi di Cloud teneteveli per voi visto che sia della prima che della seconda critica non me ne importa nulla visto che quanto scritto č sul mio blog personale.
Dopo la doverosa premessa esordisco scrivendo che, per motivi lavorativi, mi sono spostato su AWS ed è proprio studiando questo immenso ecosistema che mi è venuta la curiosità di come implementare sul cloud il mondo Swarm di Docker. Senza complicarsi troppo la vita ho trovato una soluzione già bella e pronta creata dagli stessi sviluppatori di Docker a questo link. Seguendo le facili informazioni riportate è banale importarsi il template per il CloudFormation di Aws e creare tutta la struttura:
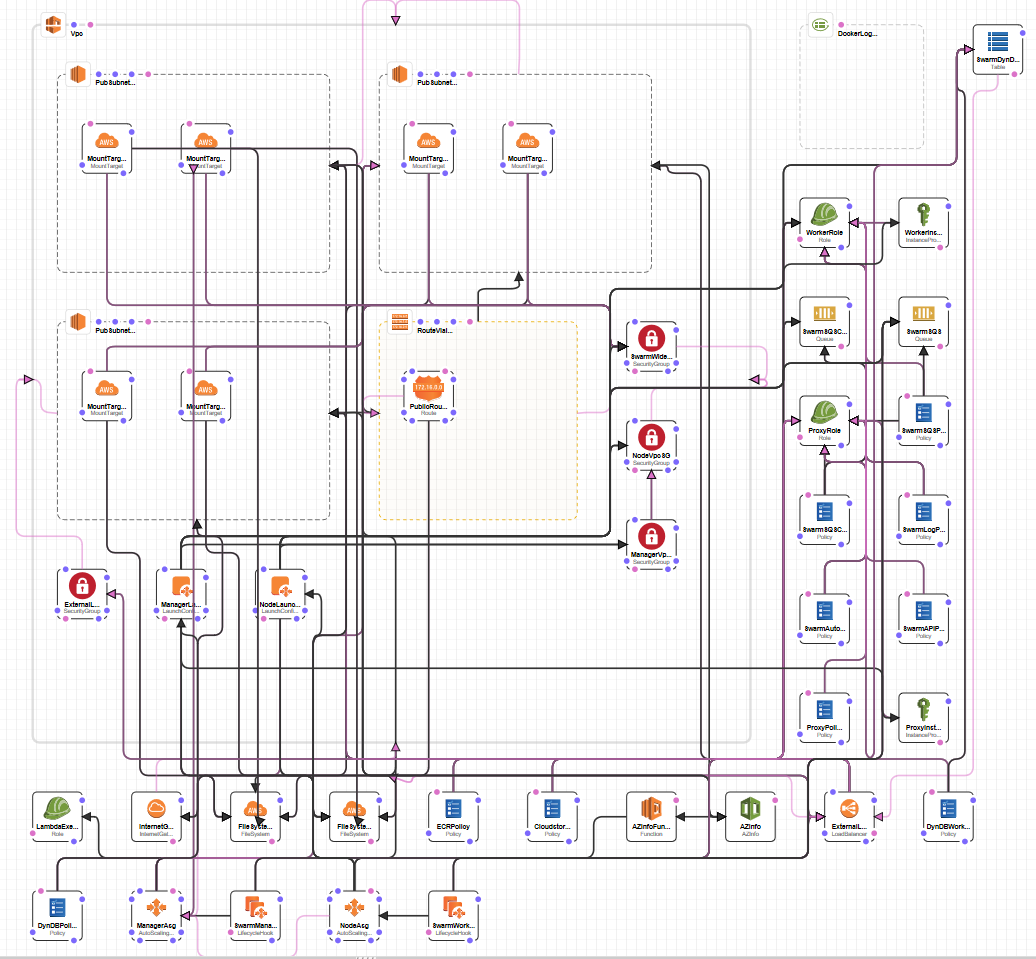
Nel momento della creazione vengono richieste varie informazioni: dal numero di nodi manager ai worker, che tipi di macchine utilizzare ecc... e avviata la procedura di creazione in una decina di minuti si ha disponibile il tutto. Ottimo, ma andando nel dettaglio ho trovato dei limiti e particolaritŕ che non mi piacevano, tra cui l'impossibilitŕ di definire le label per i singoli nodi in modo da poter assegnare container a specifiche macchine, e l'utilizzo di una marea di servizi personalizzati che nel 90% dei casi non servono cosě configurati (perché sono io di gusti difficili) e su cui la documentazione č davvero risicata (al momento del mio studio). Per questo e per altri motivi mi sono adoperato per la costruzione da zero di una mia struttura per lo Swarm di Docker in Aws per puro diletto, ripeto, per pure diletto. Quanto scriverň di seguito puň essere ripetuto con un account gratuito di AWS senza spendere un euro, anche se sfiorerň servizi che, se sfruttutati per migliorare quanto spiegato, possono essere utilizzati solo a pagamento.
Ovviamente la prima scelta per il disegno dell'infrastruttura è andata su CloudFormation. Questo servizio consente di disegnare tutta la struttura dalla rete alle speficiche delle singole macchine direttamente da un'interfaccia grafica di una pagina web. Se non piace l'uso del mouse per il disegno del tutto si può usare anche un meta linguaggio in json o yaml:
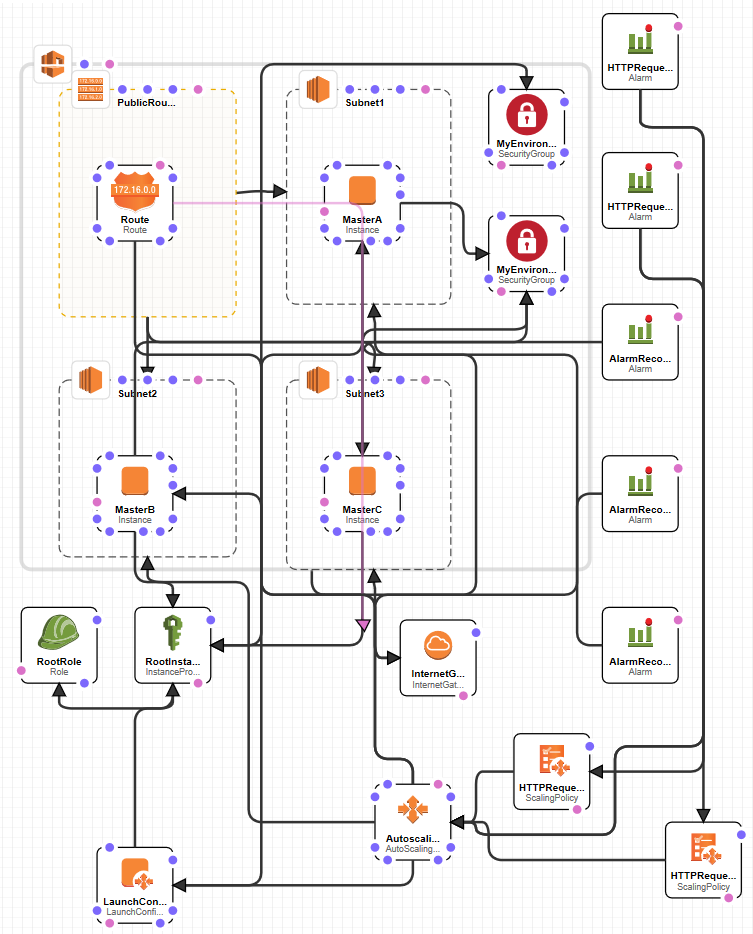
Questo č il risultato visivo di quanto voglio ottenere - per renderla visualizzabile in questo pagina ho avvicinato i vari componenti e alcune linee si sovrappongono, ma era solo per fare rendere l'idea del possibile risultato. A proposito di CloudFormation, prima di continuare alcune piccole annotazioni personali sul suo uso che si potrebbe riassumere in: comodo per scrivere banali strutture o per modificare quelle già esistenti, ma per creazioni di una certa grandezza e complessità è scomodo e lento. Per esempio, la creazioni di più VM simili tra loro è ottenibile solo con il copia/incolla non essendoci alcun linguaggio di scripting e, nel caso di modifiche, si deve riprendere la struttura precedente, mettere in update lo Stack, caricare il file e infine fare l'update. Dal canto suo AWS è in grando di modificare solo quanto serve, ma il tutto alla lunga è davvero scomodo.
Tre sono le alternative che conosco:
- Creare la struttura direttamente dalla Console di Aws e poi trasformarla in codice con CloudFormer.
- Utilizzare linguaggi di scripting (Python più Troposphere per esempio).
- Terraform.
La prima scelta è la più semplice: si crea tutta l'infrastruttura e utilizzando CloudFormer si possono selezionare gli oggetti della propria struttura per averla in formato utilizzare da CloudFormation. Funziona abbastanza bene ma non è completa: molti oggetti non vengono visti e si deve - spesso - mettere mano al codice finale per sistemare il tutto (per esempio, nelle istanze EC2 la property userdata dove è possibile inserire il proprio codice da eseguire all'avvio della VM, non viene visto e dev'essere poi inserito a mano).
La seconda scelta è una via di mezzo tra complessità e personalizzazione totale: è possibile usare il linguaggio di programmazione Python e con apposite librerie creare pressocché tutto quello che si vuole in AWS (almeno io non ho trovato nei miei test limiti in questo senso). Ma qual è il risultato dell'esecuzione di uno script con Troposphere? Json/yaml per CloudFormation. E poi nostra scelta importarlo ancora nella pagina web con tutte le sue lungaggini o usare via terminale la CLI per aggiornare lo stack.
Ultima scelta è Terraform. IMHO: qui la cosa è un po' più complessa solo dal fatto che il linguaggio di scripting per la creazione del tutto è un pseudo json. La potenza che si ha in cambio è notevole visto che Terraform è in grando di mantenere lo stato dell'infrastruttuta creata e, riavviato con le modifiche volute un proprio script, è in grado di lavorare solo sulle modifiche senza toccare quando non è necessario a differenza di quanto si è visto con Troposphere senza passare per l'interfaccia di AWS o via CLI.
Data la ma conoscenza troppo basilare di Terraform di seguito tratterò il tutto solo con Python/Troposphere. Installato Python e le librerie necessarie con pip (awacs e troposphere) con uno script č possibile creare le singole risorse di Aws. Per esempio, il codice seguente (preso dal tutorial):
from troposphere import Ref, Template
import troposphere.ec2 as ec2
t = Template()
instance = ec2.Instance("myinstance")
instance.ImageId = "ami-951945d0"
instance.InstanceType = "t1.micro"
t.add_resource(instance)Una volta eseguito creerŕ:
{
"Resources": {
"myinstance": {
"Properties": {
"ImageId": "ami-951945d0",
"InstanceType": "t1.micro"
},
"Type": "AWS::EC2::Instance"
}
}
}Che inserito in CloudFormation creerŕ una VM. Sembra una complicazione, ma per strutture veramente complesse si avrŕ a disposizione strumenti piů sicuri per la creazione del tutto. Per esempio, se avessimo bisogno di creare tre VM con lievi differenze, utilizzando CloudFormation in JSON si dovrebbe scrivere:
{
"Resources": {
"myinstance1": {
"Properties": {
"ImageId": "ami-951945d0",
"InstanceType": "t1.micro"
},
"Type": "AWS::EC2::Instance"
},
"myinstance2": {
"Properties": {
"ImageId": "ami-951945d0",
"InstanceType": "t1.micro"
},
"Type": "AWS::EC2::Instance"
},
"myinstance3": {
"Properties": {
"ImageId": "ami-951945d0",
"InstanceType": "t1.micro"
},
"Type": "AWS::EC2::Instance"
}
}
}Con Tropospehere:
from troposphere import Ref, Template import troposphere.ec2 as ec2 t = Template() for f in ["myinstance1", "myinstance2", "myinstance3"]: instance = ec2.Instance(f) instance.ImageId = "ami-951945d0" instance.InstanceType = "t1.micro" t.add_resource(instance) print(template.to_json())
Infatti č quello che farň per costruire tutta la mia infrastruttura per l'esempio che riporterň qui per creare una mia rete Swarm su AWS. Prima di mettere mano al codice parliamo di come dev'essere questa struttura. Innanzitutto per rendere il tutto piů sicuro creerň una mia rete virtuale in AWS - VPC. Una VPC puň essere creata in una determinata regione. Le regioni disponibili sono una ventina. Nel mio caso userň la regione eu-central-1 che č situata a Francoforte. Ogni regione ha a disposione le cosidette zone. Una zona si puň definire fisicamente come un datacenter. Nel caso della regione eu-central-1 sono a disposizione tre zone (ogni regione ha il suo numero variabile di zone o subnet):
- eu-central-1a
- eu-central-1b
- eu-central-1c
E' inutile aggiungere che, per fare in modo che la nostra struttura sia fault tolerace, sarebbe buona regola suddividere le risorse allocate su piů zone per evitare che un'anomalia dell'intero datacenter di una zona possa bloccare l'erogazione dei nostri servizi.
Dopo questa breve premessa č ora di mettere in piedi la mia infrastruttura di test. Innanzitutto la definizione del numero dei manager node e dei worker node. Come spiegato nei post precedenti, i manager node servono per gestire la rete in docker swarm mentre i worker dovrebbero essere utilizzati per i container da utilizzare; dovrebbe perché nulla vieta di utilizzare anche i manager per ospitare e l'esecuzione dei container. Nella seconda immagine in questo post č visibile la struttura che realizzerň: innanzitutto una VPC con all'interno tre sottoreti inserite ognuna in una singola zona della regione. All'interno di ogni sottorete una VM che fungerŕ da nodo manager. Ogni VM avrŕ dei security group per i permessi di accesso (porte Tcp/Udp in input/ouput disponibili all'interno della rete o internet. Per comoditŕ nel mio script in Python ho creato degli array di oggetti dove insesire le varie specifiche della Vpc, delle subnet, delle istance per le VM, e altre variabili da riutilizzare, ecc... Eccone una parte:
environmentString = "MyEnvironment-" # <-- Add dash here
cloudWatchIdentifier = "Stack2" # to add log to CloudWatcher
instanceTypeMaster = "t2.micro" # instance type master
instanceTypeWorker = "t2.micro" # instance type worker
DesiredCapacity = 1 # number of worker nodes for autoscaling
MinSize = 1 # min number of worker nodes for autoscaling
MaxSize = 3 # max number of worker nodes for autoscaling
labels = ["web"] # label for worker nodes: ["web","db"] creates two autoscaling group
vpc = VpcClass("myVPC", "192.168.0.0/16")
vpc.subnets.append(SubnetClass("Subnet1", "192.168.0.0/20", 0, True)) # zone 0, true -> public IP
vpc.subnets.append(SubnetClass("Subnet2", "192.168.16.0/20", 1, True)) # zone 1, ''
vpc.subnets.append(SubnetClass("Subnet3", "192.168.32.0/20", 2, True)) # zone 2, ''
vpc.subnets[0].ec2 = Ec2Machine("MasterA", "192.168.0.250", instanceTypeMaster) # name, static ip, istance type
vpc.subnets[1].ec2 = Ec2Machine("MasterB", "192.168.16.250", instanceTypeMaster)
vpc.subnets[2].ec2 = Ec2Machine("MasterC", "192.168.32.250", instanceTypeMaster)
securityMasterIngress = [
# Used from docker for Swarm Managers
SecurityGroupClass("DockerClusterManagementCommunications", vpc.CidrBlock, "tcp", 2376, 2377),
SecurityGroupClass("DockerForCommunicationAmongNodesTcp", vpc.CidrBlock, "tcp", 7946, 7946),
SecurityGroupClass("DockerForCommunicationAmongNodesUdp", vpc.CidrBlock, "udp", 7946, 7946),
SecurityGroupClass("DockerForOverlayNetworkTraffic", vpc.CidrBlock, "udp", 4789, 4789),
# My inbound ports
SecurityGroupClass("ssh", "0.0.0.0/0", "tcp", 22, 22),
SecurityGroupClass("http64000", vpc.CidrBlock, "tcp", 64000, 64000)
]
securityMasterEgress = [
SecurityGroupClass("Input", "0.0.0.0/0", "-1"),
]
securityWorkerIngress = [
# Used from docker for Swarm Workers
SecurityGroupClass("DockerForCommunicationAmongNodesTcp", vpc.CidrBlock, "tcp", 7946, 7946),
SecurityGroupClass("DockerForCommunicationAmongNodesUdp", vpc.CidrBlock, "udp", 7946, 7946),
SecurityGroupClass("DockerForOverlayNetworkTraffic", vpc.CidrBlock, "udp", 4789, 4789),
# My inbound ports
SecurityGroupClass("ssh", "0.0.0.0/0", "tcp", 22, 22),
SecurityGroupClass("testdocker", "0.0.0.0/0", "tcp", 5000, 5001),
]
securityWorkerEgress = [
SecurityGroupClass("Input", "0.0.0.0/0", "-1"),
]
Definita la CIDR per la VPC e per le singole sottoreti, definisco nei miei oggetti anche tre VM con indirizzi IP statici (per un motivo di semplicitŕ che spiegherň piů avanti), l'immagine della VM da utilizzare e il tipo di istanza di macchina da creare - AWS mette a disposizione piů immagini, per esempio Ubuntu e altre, ma anche una sua custom che utilizzerň in questi esempi, Amazon Linux 2, ottimizzata per l'utilizzo sui servizi propri di AWS (utilizzando Ubuntu, per esempio, č necessario installarli in un secondo momento); come tipo di istanza della VM, dopo aver creato un account di prova in AWS dalla durata di un anno, si avranno a disposizione alcune risorse gratuite e nel mondo delle VM le t2.micro ne fanno parte (una CPU e 1GB di ram). Anche se l'ho specificato prima, tutto quanto mostrerň in questi due post sul mio blog rientrano nel piano gratuito di test di AWS, in caso contrario lo specificherň.
L'ultima parte definisce quali porte devono essere aperte in input/output sia per i manager node che per i worker node. Nel caso dei manager le porte in entrata saranno sempre quelle e serviranno per la comunicazione tra i vari nodi con le porte standard di Docker (definite in securityMasterIngress). Per facilitare il la gestione di queste macchine ho aggiunto anche i permessi alla porta 22 per la connessione SSH per la verifica e la gestione di Docker. securityWorkerIngress oltre alle porte necessarie a Docker avrŕ bisogno d porte custom per i container da installare su queste macchine. Nell'esempio qui sopra con testdocker dň il permesso di richieste via Tcp sia alla porta 5000 che 5001. Oltre alle porte per Docker e la 22, si puň notare l'apertura della porta tcp 64000 per i nodi manager. Questo l'ho fatto per permettere la comunicazione con una mia API Rest tra le varie macchine. Prima di spiegarne il motivo č meglio fare qualche passo indietro nel mondo di Docker Swarm e sul suo funzionamento.
Anche se scritto in un mio post precedente, per avviare Docker Swarm sulle macchine si devono seguire preventiamente dei passaggi. Il primo č l'init dello swarm su una delle macchine coinvolte:
docker swarm init --advertise-addr ip
Questo comando istanzia il tutto e, se tutto č andato a buon fine, si avrŕ a schermo:
ReplY:
swarm initialized: current node (83f6hk7nraat4ikews3tm9dgm) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-0hmjrpgm14364r2kl2rkaxtm9tyy33217ew01yidn3l4qu3vaq-8e54w2m4mrwcljzbn9z2yzxrz 192.168.0.15:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.Ora č possibile connettere gli altri nodi come manager o come worker. Ma TUTTO inizia da una singola macchina. Ecco il perché ho deciso di utilizzare gli IP statici per i nodi master: avviandosi contemporaneamente le 3 macchine non potevo capire ed eseguire lo stesso codice per l'inizializzazione dello Swarm su tutte, e l'utilizzo dell'IP statico mi permette di riconoscere su quale macchina sarŕ eseguito lo script di inizializzazione e posso fare in modo che solo su una di queste macchine parta il tutto - avevo vagliato anche altre tecniche ma tutte abbisognavano di servizi aggiuntivi, cosa che volevo limitare al massimo. Ed ecco la furbata che ho pensato: dei 3 indirizzi statici per le 3 macchina manger - 192.168.0.250, 192.168.16.250 e 192.168.32.250 - solo il primo puň fare questa operazione. E tutta questa prima parte viene eseguita e controllata con un bash file.
Ed eccoci ad un altro punto della definizione di queste VM in AWS. E' possibile inserire una property adatta - userdata - il codice che sarŕ eseguito al primo avvio della macchina e non hai successivi. Nel mio caso ho bisogno che sia rieseguito anche in caso di reboot, e per permettere questo č sufficiente utilizzare la direttiva cloud-init come nel modo seguente:
Content-Type: multipart/mixed; boundary="//"
MIME-Version: 1.0
--//
Content-Type: text/cloud-config; charset="us-ascii"
MIME-Version: 1.0
Content-Transfer-Encoding: 7bit
Content-Disposition: attachment; filename="cloud-config.txt"
#cloud-config
cloud_final_modules:
- [scripts-user, always]
--//
Content-Type: text/x-shellscript; charset="us-ascii"
MIME-Version: 1.0
Content-Transfer-Encoding: 7bit
Content-Disposition: attachment; filename="userdata.txt"
#!/bin/bash
amazon-linux-extras install epel
yum update --security -y
yum install --enablerepo=epel -y nodejs
amazon-linux-extras install docker -y
service docker start
systemctl enable docker
AwsRegion=$(curl -s 169.254.169.254/latest/meta-data/placement/availability-zone | sed 's/.$//')
yum install -y git awslogs
sed -i -e "s/us-east-1/$AwsRegion/g" /etc/awslogs/awscli.conf
sed -i -e 's/log_group_name = \/var\/log\/messages/log_group_name = [CloudWatchIdentifier]/g' /etc/awslogs/awslogs.conf
sed -i -e 's/log_stream_name = {instance_id}/log_stream_name = messages-stack/g' /etc/awslogs/awslogs.conf
sed -i -e 's/\/var\/log\/messages/\/var\/log\/messages-stack/g' /etc/awslogs/awslogs.conf
systemctl start awslogsd
systemctl enable awslogsd.service
echo 'Start service in [nameMaster]' > /var/log/messages-stack
#git config --system credential.helper '!aws codecommit credential-helper $@'
#git config --system credential.UseHttpPath true
rm -rf /scripts
mkdir /scripts
cd /scripts
git clone https://github.com/sbraer/AwsNodeJsCodeDeploy.git
cd AwsNodeJsCodeDeploy/
npm install
chmod +x create_swarm.sh
chmod +x update_service.sh
crontab -r
chmod +x docker_login.sh
./docker_login.sh
(crontab -l 2>/dev/null; echo "0 */6 * * * /scripts/AwsNodeJsCodeDeploy/docker_login.sh -with args") | crontab -
./create_swarm.sh [ipPrivateList]
--//Il codice vero e proprio č quello dopo il shebang unix - #!/bin/bash. Lei sei righe successiva installano NodeJs (attivando i vari repository necessari) e Docker. Nella variabile AwsRegion memorizzo la regione in cui č stata avviata la macchina - la chiamata all'url 169.254.169.254 č una chiamata disponibile all'interno della VM per avere i Metadata per quell'istanza, maggiori info qui. Di seguito viene installato il servizio AWSLOG, questo č necessario per poter inviare i nostro log da questa macchina al servizio centralizzato di log di Aws. In questo modo, qualsiasi testo inserito nel file /var/log/messages-stack sarŕ inviato anche a questo servizio, per la verifica di eventuali anomalie.
Le due righe commentate per git sono una feature disponibile in AWS utilizzabile nel caso si scelga di usare CodeCommit di AWS per lo store dei propri progetti. Se avessi utilizzato CodeCommit, che necessita di credenziali per essere scaricato, avrei dovuto inserire nello script qui sopra anche le credenziali che č tutto tranne sicuro. Aws, per risolvere questo problema con CodeCommit, permette di aggiungere una role particolare all'istanza della VM che gli permetterŕ di scaricare il repository in git senza dover insererile le credenziali:
{
"PolicyDocument": {
"Statement": [
{
"Action": [
"codecommit:ListRepositories"
],
"Effect": "Allow",
"Resource": [
"*"
]
},
{
"Action": [
"codecommit:GitPull"
],
"Effect": "Allow",
"Resource": [
"arn:aws:codecommit:eu-central-1:XXXXXXXXXXXX:AwsCodeTest"
]
}
]
},
"PolicyName": "GitPolicy"
}Questa policy da inserie nella role, permette solo il git pull del repository presente in Resource, senza poter fare altro. Ora git per avere le credenziali necessarie deve solo eseguire le due righe viste prima:
git config --system credential.helper '!aws codecommit credential-helper $@' git config --system credential.UseHttpPath true
Fine. Il git pull successivo solo a quel repository funzionerŕ senza problemi. Nel mio esempio ho inserito un mio repository pubblico di git e dunque le due righe non sono necessarie, perň č interessante sapere questa feature di AWS.
Prima di trovarsi in futuro di fronte ad amare soprese si deve prestare molta attenzione all'uso di git interno di AWS con una role come la precedente. Innanzitutto AWS dŕ la possibilitŕ di creare gratuitamente cinque utenti per git. Creando una role come la precedente per permette l'accesso da altre risorse, si fa in modo che, dietro la quinte, venga creato un utente per l'accesso a git (questo utente si attiverŕ solo quando i comandi precedenti - git config - saranno utilizzati). Su questo punto č bene prestare molta attenzione, perché se deleghiamo a CloudFormation la creazione della role come ho fatto nel mio codice, in caso di cancellazione e creazione ex novo dello stack, AWS creerŕ un nuovo utente ogni volta. Il problema č che dal sesto utente si inizia a pagare. Questo non č un problema se la role qui sopra viene definita fuori dallo script per CloudFormation o si aggiorna ogni volta lo stack invede di crearlo da capo ogni volta. Per non rischiare di essere frainteso, ripeto, non č la role qui sopra che crea il nuovo utente per GIT, ma č l'esecuzione del codice:
git config --system credential.helper '!aws codecommit credential-helper $@' git config --system credential.UseHttpPath true
Nel mio codice questo č commentato, dunque non si corrono pericoli.
Tornando sul mio script precendente, successivamente viene scaricato il mio repository AwsNodeJsCodeDeploy che contiene un mio script in Nodejs e altri script bash utili per la creazione dello Swarm: create_swarm.sh - update_swarm.sh lo vedremo nella prossima parte di questo post. Infine viene eseguito lo script docker_login.sh e inserito in cron, perché venga eseguito ogni sei ore; ma perché? Tratterň la cosa nel prossimo post quando userň un'ummagine docker salvata du Ecr (container registry docker interno di Aws), per ora basti sapere che č un altra feature di Aws con container privati per la loro gestione senza utilizzare credenziali in chiaro, proprio come visto poco sopra per il CodeCommit di AWS. Il mio script in NodeJs avvia il web server express rendendo disponibile degli endpoint API REST:
const express = require("express"),
bodyParser = require("body-parser"),
dockerSwarmApi = require("./routes/dockerswarm.js"),
testApi = require("./routes/test.js");
const app = express();
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
dockerSwarmApi(app);
testApi(app);
app.use((_, res) => {
res.sendStatus(404);
});
// PORT=3000 node app.js
const port = process.env.PORT || 64000;
const server = app.listen(port, () => {
console.log("app running on port: ", server.address().port);
});testApi contiene una chiamata banale per controllare che lo script funziona correttamente:
const appRouter = (app) => {
app.get("/api/test", (_, res) => {
res.status(200).send({ test: 1 });
});
}
module.exports = appRouter;dockerSwarmApi contiene le chiamate per la creazione dello Swarm e per il suo aggiornamento. Per ora mostro solo una chiamata:
app.get("/api/dockerswarm/token/:type", (req, res) => {
const { type } = req.params;
if (!type || (type !== "worker" && type !== "manager")) {
res.status(400).send({ message: 'invalid token type supplied (manager|worker)' });
}
else {
const dockerCommand = `docker swarm join-token ${type} | sed -n 3p | grep -Po 'docker swarm join --token \\K[^\\s]*'`;
execFunction(dockerCommand, res, true);
}
});
Con questa chiamata si ottiene la tokenkey da utilizzare per aggiungere nodi manager e worker a Docker Swarm. Se si č seguito attentamente quanto scritto finora (lo so, troppa roba e la confusione regnerŕ sovrana), all'avvio delle tre macchine manager, come giŕ scritto, solo la prima avvierŕ e instanzierŕ lo Swarm in Docker, le altre macchine, comprese i nodi worker, per connettersi, faranno una chiamata a questa macchina, o ad altre manager, per avere la tokenkey e connettersi allo Swarm. Questo avviene analizzando il codice nello script bash create_swarm.sh per i manager:
#!/bin/bash
IPMASTERA=$1
IPMASTERB=$2
IPMASTERC=$3
if [ -z "$IPMASTERB" ]; then
IPMASTERB=""
fi
if [ -z "$IPMASTERC" ]; then
IPMASTERC=""
fi
ip=$(curl http://169.254.169.254/latest/meta-data/local-ipv4)
if [ $ip = $IPMASTERA ]; then
master1=$IPMASTERB # b
master2=$IPMASTERC # c
elif [ $ip = $IPMASTERB ]; then
master1=$IPMASTERA # a
master2=$IPMASTERC # c
elif [ $ip = $IPMASTERC ]; then
master1=$IPMASTERA # a
master2=$IPMASTERB # b
else
exit 255
fi
docker node ls
if [ $? -eq 0 ]; then
eval "docker network create --driver overlay mynet"
echo "Swarm already started and joined"
echo "$ip already started and joined" >> /var/log/messages-stack
node app.js &
exit 0
fi
echo "Check..."
echo "$ip Check if there is docker swarm available..." >> /var/log/messages-stack
writeFiles="false"
files=($master1 $master2)
while true
do
for i in "${files[@]}"
do
echo "Try to connect to $i..."
echo "$ip Try to connect to $i..." >> /var/log/messages-stack
code=$(curl --fail --connect-timeout 5 http://$i:64000/api/dockerswarm/token/manager)
if [ ! -z "$code" ]; then
echo "API Rest replied. Try to join to manager..."
echo "$ip API Rest replied. Try to join to manager..." >> /var/log/messages-stack
eval "docker swarm join --token $code $i"
if [ $? -eq 0 ]; then
echo "$ip joined!" >> /var/log/messages-stack
eval "docker network create --driver overlay mynet"
writeFiles="true"
break
fi
fi
done
if [[ ! "$writeFiles" = "true" && "$ip" = $IPMASTERA ]]; then
docker swarm init --advertise-addr $ip
if [ ! $? -eq 0 ]; then
echo "$ip Error creating Swarm" >> /var/log/messages-stack
echo "Error when create Swarm"
exit 255
fi
echo "$ip Swarm created" >> /var/log/messages-stack
eval "docker network create --driver overlay mynet"
break
fi
if [ "$writeFiles" = "true" ]; then
break
fi
echo "Wait 30 seconds..."
echo "$ip Wait 30 seconds..." >> /var/log/messages-stack
sleep 30
done
echo "$ip Start API Rest" >> /var/log/messages-stack
node app.js &
exit 0
Semplifico: si controlla l'IP su cui gira questo script che accetta tre parametri - di cui solo il primo obbligatorio - che sono IP dei tre nodi manager. Quindi si controlla che la macchina non sia giŕ nella rete Swarm, in caso negativo chiama uno per uno le macchine controllando che qualcuna risponda con la tokenkey da utilizzare per fare il join alla rete. Se nessuna macchina risponde, viene verificato che la macchina attuale non stia utilizzando l'ip principale designato alla creazione del tutto, se č cosě, viene istanziato il tutto, altrimenti si aspetta trenta secondi e si prova ancora la connessione alle altre macchine.
Le macchine worker hanno uno script piů semplice - join_to_swarm.sh:
#!/bin/bash
echo "join to swarm..."
w1=$1
w2=$2
w3=$3
w=($w1 $w2 $w3)
exitFile="false"
while true
do
for i in "${w[@]}"
do
code=$(curl --fail --connect-timeout 5 http://$i:64000/api/dockerswarm/token/worker)
if [ ! -z "$code" ]; then
echo "API Rest repied. Try to join to manager..."
eval "docker swarm join --token $code $i"
if [ $? -eq 0 ]; then
echo "joined!"
exitFile="true"
break
fi
fi
done
if [ "$exitFile" = "true" ]; then
break
fi
echo "Wait 30 seconds..."
sleep 30
doneAnche qui vengono attesi tre parametri (che sono gli IP statici delle tre macchine manager), quindi una a una si chiama con curl la API vista prima per avere la tokenkey con cui collegarsi alla rete Swarm. Altrimenti si aspetta trenta secondi. Per motivi di sicurezza solo le macchine all'interno della VPC potranno collegarsi a questa API che, ripeto, girerŕ solo sulle macchine manager, č questo grazie alla policy vista prima - il secondo parametro č il riferimento al CIDR della VPC, per esempio 192.168.0.0/16:
SecurityGroupClass("http64000", vpc.CidrBlock, "tcp", 64000, 64000)E' ora di vedere lo script bash di avvio per le macchine worker:
#!/bin/bash yum update --security -y amazon-linux-extras install docker -y sed -i '/ExecStart=\/usr\/bin\/dockerd $OPTIONS $DOCKER_STORAGE_OPTIONS/cExecStart=\/usr\/bin\/dockerd $OPTIONS $DOCKER_STORAGE_OPTIONS --label=[label]=true' /lib/systemd/system/docker.service service docker start systemctl enable docker yum install -y git #git config --system credential.helper '!aws codecommit credential-helper $@' #git config --system credential.UseHttpPath true mkdir /scripts cd /scripts git clone https://github.com/sbraer/AwsNodeJsCodeDeploy.git cd AwsNodeJsCodeDeploy/ chmod +x join_to_swarm.sh ./join_to_swarm.sh [ipPrivateList]
Molto piů breve e semplice. Inannzitutto vengono installati gli aggiornamenti di sicurezza e Docker. La riga che inzia con sed non fa altro che modificare nel file di configurazione di Docker - /lib/systemd/system/docker.service - la label da assegnare alle macchine. Il valore da inserire č la stringa [label] su cui sarŕ fatto il replace sul valore reale dallo script in Python/Troposphere. Successivamente si installa anche git e si scarica la soluzione contenente i vari file per il join alla rete - join_to_swarm.sh visto poco sopra.
Finora non ho mai detto nulla per le machine worker. Ho solo mostrato, senza molti dettagli, nel file di configurazione in Python, l'array:
labels = ["web"]
web č la stringa che sarŕ sostituita nello script visto sopra per la label. Essendo un array, avrei potuto anche scrivere:
labels = ["web", "db"]
Entrando nel dettaglio per la creazione delle macchine worker, ho preferito non creare nulla di statico e utilizzare l'autoscaling. Questo consente di creare un numero dinamico di macchine e di poterne modificare il numero a seconda le proprie esigenze:
- Staticamente: dalla console (o via CLI) si puň modificare a proprio piacimento il numero.
- Schedulazione: modificarne il numero in determinate ore o giorni per contrastare attivamente eventuali carichi di richieste in determinare fasce di orario o di giorni (fine settimana, inizio mese, festivitŕ, ecc...).
- Dinamicamente: č possibile inserire appositi allarmi che superate certe soglie di traffico, rete o altro, attivi automaticamente nuove macchine su cui suddividere il carico.
Nel mio caso ho utilizzato l'autoscaling dinamico basandomi sull'utilizzo della banda: superata una certa soglia per piů di un minuto, vengono avviate nuove macchine che automaticamente faranno il join alla rete swarm. Semplice č la modifica nel caso volessi utilizzare la cpu come controllo, ma l'utilizzo di questo o altre tecniche non č assoluta e va scelta dopo un'attenta analisi delle app che girano su quel server - č solo per semplicitŕ che io ho utilizzato il traffico di rete.
Di base, nello script in Python:
DesiredCapacity = 1 MinSize = 1 MaxSize = 3
E i dettagli per l'autoscaling, in cui la prima definisce la tipologia di macchina, i security groups per i permessi, quindi l'UserData, in cui č inserito il codice visto precedentemente per l'instazzione e la configurazione delle label in Docker (con un semplice replace, modifico i valori):
for f in labels:
LaunchConfig = template.add_resource(LaunchConfiguration(
"LaunchConfiguration"+f,
ImageId=FindInMap("RegionMap", Ref("AWS::Region"), "AMI"),
InstanceType=instanceTypeWorker,
KeyName=Ref(keyPar_param),
IamInstanceProfile=Ref(rootInstanceProfile),
SecurityGroups=[Ref(instanceSecurityWorkerGroup)],
UserData=Base64(USER_DATA_WORKER.replace("[ipPrivateList]", ipPrivateList).replace("[label]", f)),
BlockDeviceMappings=[
ec2.BlockDeviceMapping(
DeviceName="/dev/xvda",
Ebs=ec2.EBSBlockDevice(
VolumeSize="8"
)
)
]
)
)In questa sezione vengono definite il numero di macchine con le variabili viste prime, piů altre property.
AutoscalingGroupX = template.add_resource(AutoScalingGroup(
"AutoscalingGroup"+f,
Cooldown=300,
HealthCheckGracePeriod=300,
DesiredCapacity=DesiredCapacity,
MinSize=MinSize,
MaxSize=MaxSize,
Tags=[
Tag("Name", environmentString+"AutoscalingGroup"+f, True)
],
LaunchConfigurationName=Ref(LaunchConfig),
VPCZoneIdentifier=subnetsList,
# LoadBalancerNames=[Ref(LoadBalancer)],
#AvailabilityZones=subnetsList,
HealthCheckType="EC2",
UpdatePolicy=UpdatePolicy(
AutoScalingReplacingUpdate=AutoScalingReplacingUpdate(
WillReplace=True,
),
AutoScalingRollingUpdate=AutoScalingRollingUpdate(
PauseTime='PT5M',
MinInstancesInService="1",
MaxBatchSize='1',
WaitOnResourceSignals=True
)
)
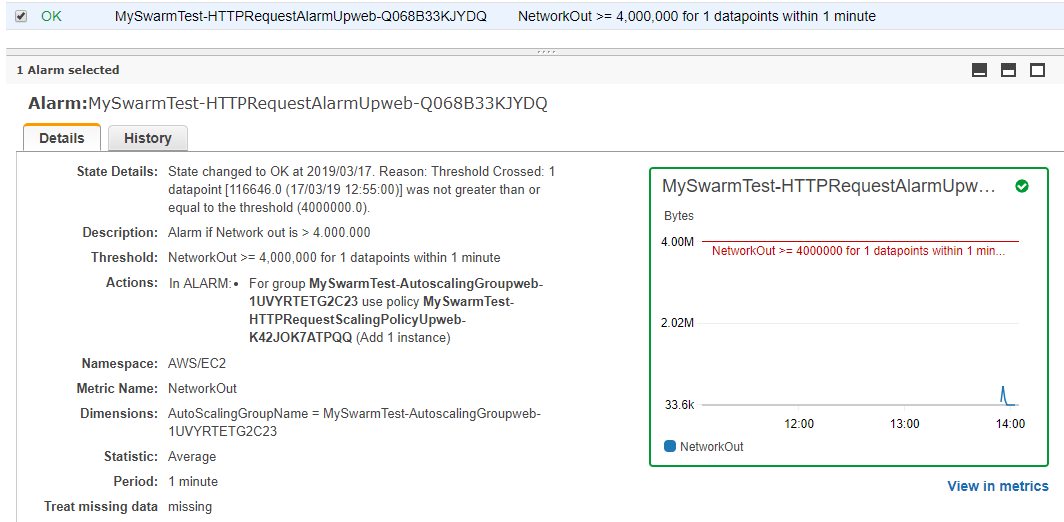
))Qui nel dettaglio ho inserito gli allarmi che faranno scattare l'aumento o la diminuzione del numero delle macchine, per esempio, in HTTPRequestAlarmUp imposto l'allarme quando saranno superati i quattro milioni di byte di trasferimento al minuto. Cosě la sua riduzione quando, in un minuto, le singole macchine invieranno meno di un milione di byte.
ScalePolicyUp = template.add_resource(ScalingPolicy(
"HTTPRequestScalingPolicyUp"+f,
AutoScalingGroupName=Ref(AutoscalingGroupX),
AdjustmentType="ChangeInCapacity",
Cooldown="300",
ScalingAdjustment="1"
))
ScalePolicyDown = template.add_resource(ScalingPolicy(
"HTTPRequestScalingPolicyDown"+f,
AutoScalingGroupName=Ref(AutoscalingGroupX),
AdjustmentType="ChangeInCapacity",
Cooldown="300",
ScalingAdjustment="-1"
))
HTTPRequestAlarmUp = template.add_resource(Alarm(
"HTTPRequestAlarmUp"+f,
AlarmDescription="Alarm if Network out is > 4.000.000",
Namespace="AWS/EC2",
MetricName="NetworkOut",
Dimensions=[
MetricDimension(
Name="AutoScalingGroupName",
Value=Ref(AutoscalingGroupX)
),
],
Statistic="Average",
Period="60", # 1 minute
EvaluationPeriods="1",
Threshold="4000000",
ComparisonOperator="GreaterThanOrEqualToThreshold",
AlarmActions=[Ref(ScalePolicyUp)]
))
HTTPRequestAlarmDown = template.add_resource(Alarm(
"HTTPRequestAlarmDown"+f,
AlarmDescription="Alarm if Network is < 1.000.000",
Namespace="AWS/EC2",
MetricName="NetworkOut",
Dimensions=[
MetricDimension(
Name="AutoScalingGroupName",
Value=Ref(AutoscalingGroupX)
),
],
Statistic="Average",
Period="60", # 1 minute
EvaluationPeriods="1",
Threshold="1000000",
ComparisonOperator="LessThanOrEqualToThreshold",
AlarmActions=[Ref(ScalePolicyDown)]
))Ora č il momento di avviare il tutto. Per una mia scelta personale ho preferito inserire nello script Python i parametri della configurazione ben sapendo che la cosa era possibile anche da CloudFormation. Nel mio caso per provare il tutto farň in modo di creare tre macchine manager (anche se nulla mi vieta di commentare la creazione del secondo e terzo nodo master), e con l'autoscaling una macchina avviata di default con un massimo di tre (questa configurazione č stata creata dallo script che č possibile scaricare anche dal link alla fine di questo post) e queste macchina abbiamo come label web. Preso il codice Json generato e copiato all'interno di CloudFormation (o salvandolo su file e utilizzando l'AWS CLI per la generazione dello stack da linea di comando), dopo la richiesta di parametri come il nome dello stack e la key usata per la connessione SSH, l'ultima richiesta obbligatoria č accettare che CloudFormation possa modificare e create le IAM resource:

Questa richiesta viene fatta quando nel codice per la definizione dello Stack sono inserite anche role IAM che danno accesso particolare alle varie risorse in AWS: questo consentirebbe a qualsiasi template la modifica di risorse giŕ presenti in AWS. Nel mio caso:
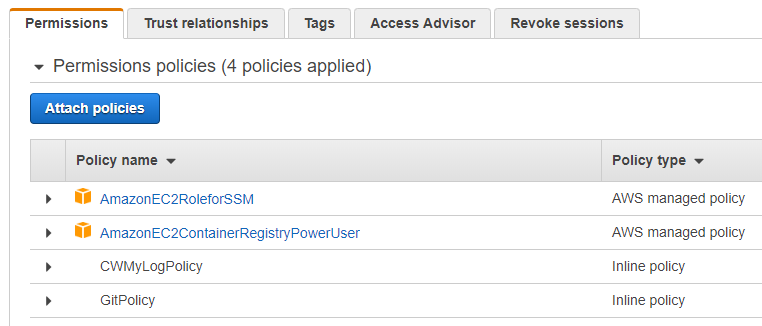
La prima role - AmazonEC2RoleforSSM - viene utilizzato per l'accesso remoto direttamente dall'interfaccia web di AWS (vedremo poi l'utilitŕ). AmazonEC2ContainerRegistryPowerUser servirŕ alle VM per accedere a ECR (il registry docker privato di AWS) di cui parlerň nella seconda parte. CWMyLogPolicy č una role contenente le policy per poter inviare i log a CloudWatch:
{
"Statement": [
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Resource": [
"arn:aws:logs:*:*:*"
],
"Effect": "Allow"
}
]
}Infine GitPolicy che, come scritto prima, permette alle VM l'eventuale accesso a repository GIT di CodeCommit di AWS.
E' ora di passare alla creazione dello stack:
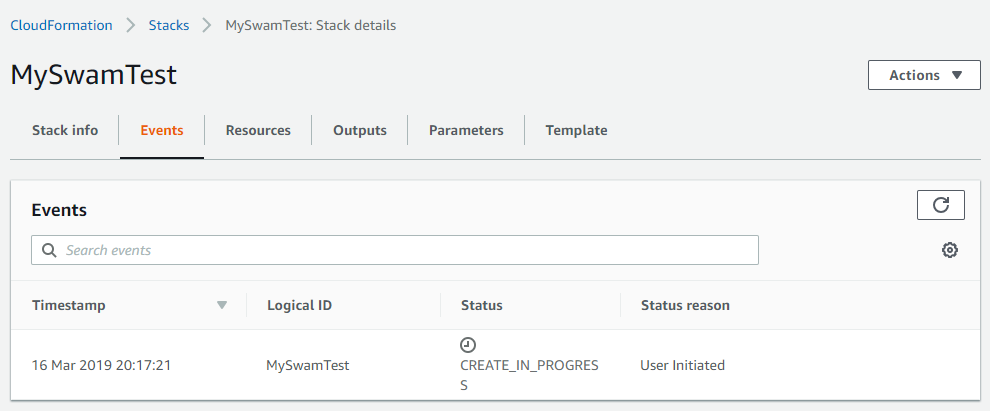
Status passerŕ in una decina di minuti da CREATE_IN_PROGRESS a CREATE_COMPLETE. Nello script avevo aggiunto anche i parametri di output:
outputs = []
outputs.append(Output(
"VPC",
Description="A reference to the created VPC",
Value=Ref(VPC),
))
for f in vpc.subnets:
if f.ec2 is not None:
outputs.append(Output(
"PublicIP"+f.ec2.name,
Description="Public IP address of the newly created EC2 instance: " + f.ec2.name,
Value=GetAtt(f.ec2.instance, "PublicIp")
)
)
for f in vpc.subnets:
outputs.append(Output(
f.name,
Description="A reference to the public subnet in the availability Zone",
Value=Ref(f.instance)
)
)
template.add_output(outputs)
Tra cui il nome della VPC creata, cosě come le SUBNET e gli IP pubblici per i nodi master. Dal tab apposito - OUTPUT - saranno mostrate queste informazioni:
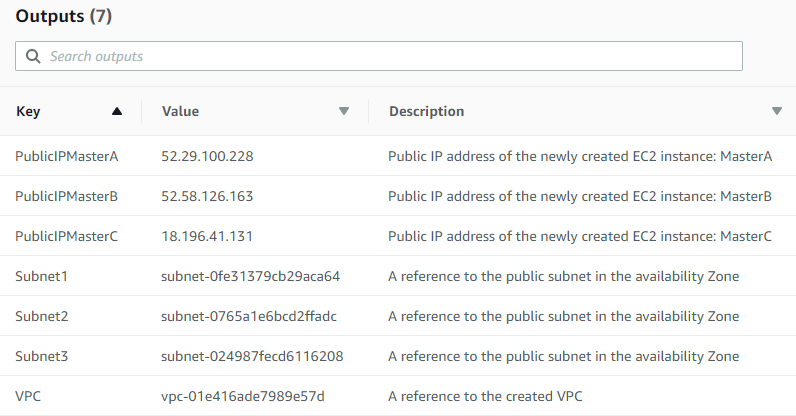
Avendo IP pubblico, č possibile connettersi via SSH ad una di queste macchine manager e verificare che Docker e la rete Swarm sia avviata e configurata:
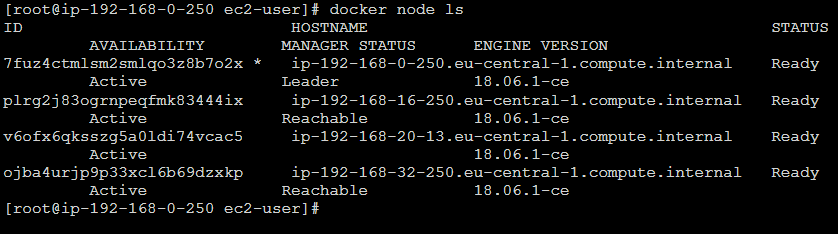
Le tre macchine manager sono riconoscibili dall'ip statico (192.168.0.250, 192.168.16.250, 192.168.32.250), mentre la macchina worker avrŕ un ip dinamico (192.168.20.13 nell'esempio qui sopra). Ma ora controllo che questa macchina sia configurata sotto la giusta label:

Ecco la macchina riconosciuta. Prima di passare agli esempi un piccolo passo indietro. Come scritto precedentemente ho inserito anche il log in modo da controllare se tutto ha funzionato e per verificare immediatamente eventuali anomalie. Andando in CloudWatch, nei logs, ecco una parte dell'output delle mie macchine:
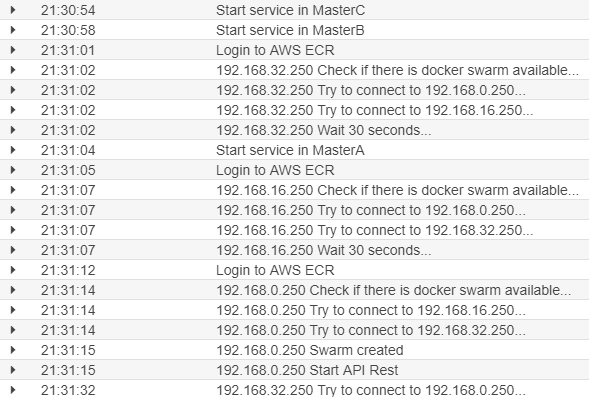
Notare che l'ordine di avvio vede il server principale - MasterA - avviene dopo gli altri due nodi master. Infatti, questi due server, cercano di connettersi agli altri nodi master alla ricerca di un'istanza attiva, non trovandone si mettono in pausa per 30 secondi. Solo all'avvio del server MasterA - IP 192.168.0.250 - dopo aver cercato inutilmente altri nodi master, crea lui la rete Swarm e avvia l'app in nodejs in grado di ricevere le chiamate per avere il token. Ed ecco il join di queste due macchine:
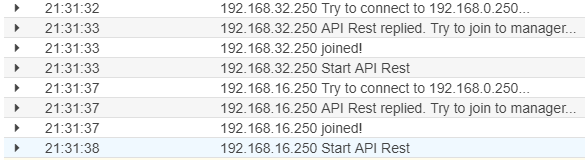
E' ora di iniziare a fare sul serio. Controllo che l'Auto Scaling sia configurato e avviato correttamente:
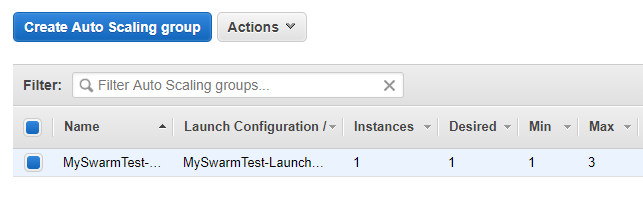
Come da configurazione č avviata una macchina e il massimo numero di macchine che l'auto scaling puň avviare č tre. Controllo pure in CloudWatch l'Alarm:
Da tradizionalista riprendo mano agli esempi dei post precedenti per controllare se funziona tutto:
docker service create --mode global --constraint \ engine.labels.web==true --name app0 -p 5000:5000 \ sbraer/aspnetcorelinux:api1
Alla fine controllo che il servizio sia attivo:

Testando con il comando curl controllo che funzioni il tutto:
# curl localhost:5000/api/systeminfo
[{"guid":"f5f2226e-6b48-4025-b3cb-9137d7ea64f8","dateTime":"2019-03-16T20:45:19.349016+00:00"}]Anche se spiegato nei post citati ad inizio di questo, voglio ripetermi sull'utilitŕ del parametro global per --mode. Questo obbliga l'installazione l'avvio di un solo container per ogni macchina che fa parte della rete Swarm, avendo aggiunto il parametro constraint, solo sulle macchine che rispettano la label lě definita. Altro punto positivo e utile in questo caso, č che qualsiasi nuova macchina creata e aggiunta allo Swarm con quella label, sarŕ avviato un container automaticamente.
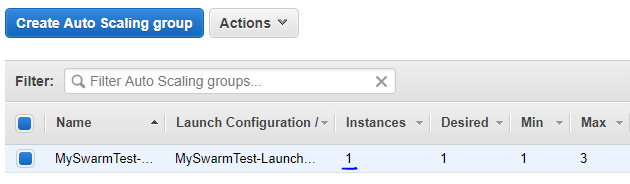
C'č soddisfazione. Ma č anche ora di verificare se l'autoscaling funziona. Per fare questo usiamo il tool apache ab (per usi piů avanzati č preferibile Artillery) e proviamo a simulare per cinque minuti un alto carico di chiamate da un'altra macchina virtuale:
ab -n 500000 -c 15 -t 300 -s 120 http://localhost:5000/api/systeminfoDopo un paio di minuti č possibile vedere che l'autoscaling sta facendo il suo lavoro e un'altra macchina č stata creata:
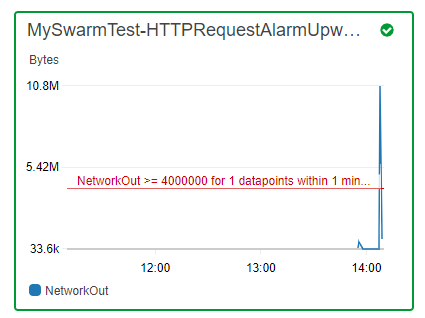
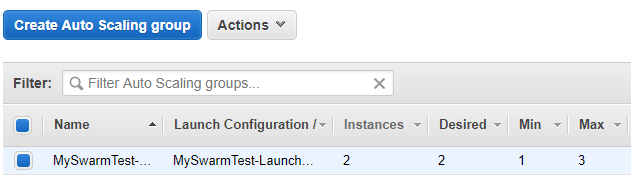
Ecco che la nuova VM č stata avviata (ora in Instances sono due le macchine avviate):
Verifico da un nodo manager che sia sia collegato:
docker node ls 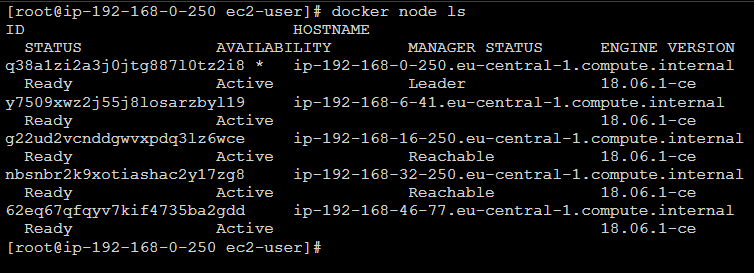
Ecco che ora sono due i worker node (192.168.6.41 e 192.168.46.77), avviati in due zone diverse.
Alla fine delle richieste, dopo un paio di minuti, si potrebbe vedere come automaticamente l'autoscaling ha spento una delle due macchine:
E' ora di parlare di sicurezza. Quanto visto finora non passerebbe qualsiasi controllo per la sicurezza per molteplici problemi, il primo tra tutti č che tutte le macchine sono esposte pubblicamente su Internet - io mi ero collegato via SSH direttamente ad una macchina manager per i test. Anche le macchine worker sono tutte esposte con IP pubblico su internet. Questa scelta č stata obbligata per rimanere nelle risorse gratuite messe a disposizione con l'account di AWS - sempreché qualcuno volesse provare quanto scritto finora. Nella creazione dell'infrastruttura vista finora ho fatto in modo che il routing di default della VPC (e di tutti i suoi componenti) potesse essere pure pubblica, quando, per la sicurezza, queste avrebbero dovute essere private e quindi inaccessibili all'esterno. La chiusura in subnet private avrebbe comportato sě la libera connessione tra le macchine coinvolte nella rete Swarm, ma avrebbe impedito qualsiasi accesso a Internet per l'installazioni dei vari pacchetti per l'avvio e la configurazione delle macchine. Questo problema ha una facile soluzione: NAT Gateways. Questo avrebbe permesso l'accesso dalle VM a Internet senza esporre punti vulnerabili alle stesse; ma nel mio caso ho preferito non usare il NAT perché comporta un costo, anche la sola attivazione, e per GB trasferiti. Dopo l'attivazione del NAT le nostre macchine sarebbero state al sicuro, aggiornate e funzionanti all'interno della loro rete privata, e per rendere fruibile su internet i servizi? Anche qui c'č una semplice soluzione: con l'Elastic Load Balancing di AWS. Per ogni gruppo di macchine in autoscaling č sufficiente collegare una nuova istanza dell'Application Load Balancer perché uno o piů servizi sia utilizzabile anche pubblicamente su Internet. E per l'accesso ai nodi manager? Sono disponibili piů soluzioni, dalla creazione di un accesso VPN alla possibilitŕ di connettersi con un terminale direttamente dall'interfaccia web di AWS.
Quest'ultima tecnica č molto comoda e per operazioni di manutenzione di base č piů che sufficiente. Per poterla utilizzare č necessario creare una ROLE IAM con all'interno la Policy come descritto qui e come ho fatto nel mio script. Quindi, assegnata questa ROLE alle istanze delle macchine virtuali, avviate, andare nell'AWS System manager
Avvia la sessione nel browser:
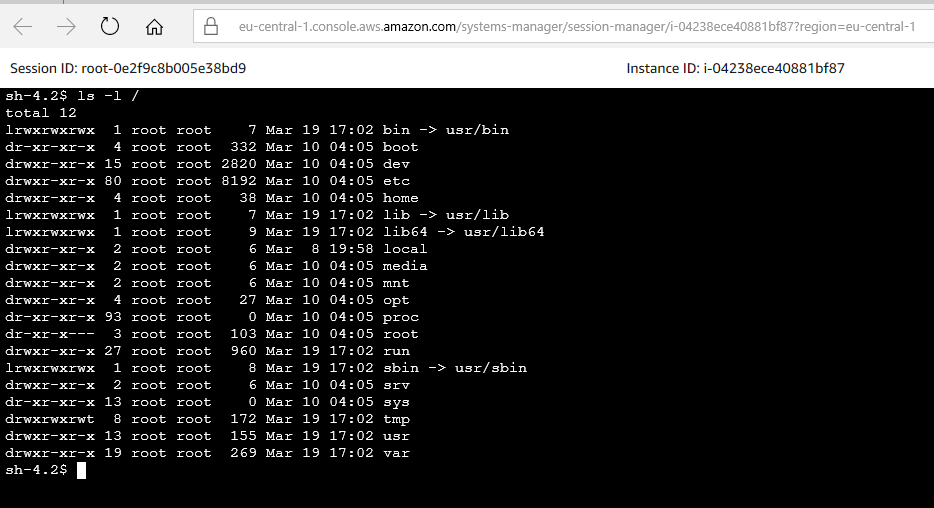
Arrivati a questo punto, tutto č perfetto, funziona il tutto, ma per avviare qualsiasi container docker č necessario entrare su una macchina manager e, a mano, digitare i comandi di docker per avviare o aggiornare il tutto. Se si volesse automatizzare tutto in un contesto CD, si potranno utilizzare altri strumenti di AWS come la CodePipeline, ma di questo volevo parlare nel prossimo post che uscirŕ, spero, tra meno di due anni.
Il codice (compreso lo script in python) č disponibile qui:
https://github.com/sbraer/AwsNodeJsCodeDeploy

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
- AWS Lambda Custom Rutime in C++, il 18 giugno 2022 alle 09:52
- AWS Lambda Cold Start in C# e..., l'11 giugno 2022 alle 12:28
- AWS e Docker Cloudstor, il 10 novembre 2019 alle 13:55
- Docker Swarm con AWS - Parte 2, il 27 maggio 2019 alle 18:00