
Seneca.js, message broker e infine Consul
Premessa: quanto qui esposto si basa su mie esperienze dirette e, spesso, di miei personali punti di vista, dunque non sparate sul pianista.
Dopo la doverosa premessa, visti i temi trattati, questo post e dedicato alla chiusura della trilogia dedicato ai message broker, iniziato con il primo post sull'argomento, approfondito con il secondo post e infine questo, per proiettarsi poi verso altre mete che l'architettura dei microservice ci obbliga(!?!?) raggiungere.
Un passo indietro: in quei post utilizzavo un message broker come RabbitMQ per la gestione dei messaggi. Se si ricorda quanto scritto, la parte piů complicata del loro utilizzo era la gestione asincrona obbligatoria che aveva il tutto: invio del messaggio/evento di ricezione della risposta. Per il mondo del Framework .net di Microsoft mi ero creato una libreria che facilitava questo lavoro mentre per la sua origine di per sé asincrona di node.js, il tutto era piů semplice - rimando al secondo post per spiegazioni dettagliate.
Visto che in quest'ultimo periodo sto parecchio tempo su node.js, ho avuto il piacere di provare/usare il framework seneca.js. Brevemente, questo framework permette, con la configurazione di base, di usare le RPC - remote procedure call - in modo quasi banale tra processi sulla stessa macchina (si vedrŕ tra poco come superare questo limite).
Prendendo gli esempi di base, in una directory creata ad hoc, su una macchina su cui sono installati e funzionanti sia node.js che npm, si installa seneca.js con un unico comando:
npm install seneca
Quindi creiamo lo script dove avremo la funzione, o le funzioni, da richiamare:
var seneca = require('seneca')()
seneca.add({role: 'math', cmd: 'sum'}, function (msg, respond) {
var sum = msg.left + msg.right
console.log(">> "+sum);
respond(null, {answer: sum})
})
seneca.listen();La prima riga istanzia il framework, mentre la seconda riga definisce il metodo che sarŕ possibile richiamare da remoto. E' possibile inserire tutti metodi che vogliamo definendoli come stringa, come qui sopra. Per esempio:
{role: 'math', cmd: 'sum'}
{role: 'math', cmd: 'avg'}
{role: 'string', cmd: 'len'}L'uso di role e cmd č solo una convenzione data dalla documentazione di questo framework, nulla ci vieta di scrivere:
{class: 'math', method: 'sum'}
{class: 'math', method: 'avg'}
{namespace:'system', class: 'string', cmd: 'len'}Infine, per poter richiamare il metodo definito nell'esempio qui sopra, in un altro file, inseriamo questo codice:
var seneca = require('seneca')()
seneca.client();
seneca.act({role: 'math', cmd: 'sum', left: 1, right: 2}, function (err, result) {
if (err) return console.error(err)
console.log(result)
})add viene utilizzato per inserire i metodi disponibili in seneca.js, act per poter richiamare tali metodi. Eseguito questo codice il funzionamento sarŕ molto semplice: seneca.js cercherŕ il metodo che vogliamo chiamare, se č disponibile invia la richiesta al processo prima avviato, e una volta ricevuta risposta, sarŕ utilizzata come parametro per richiamare una nostra funzione - nell'esempio viene richiamato il comando prima definito che esegue la somma di due numeri.
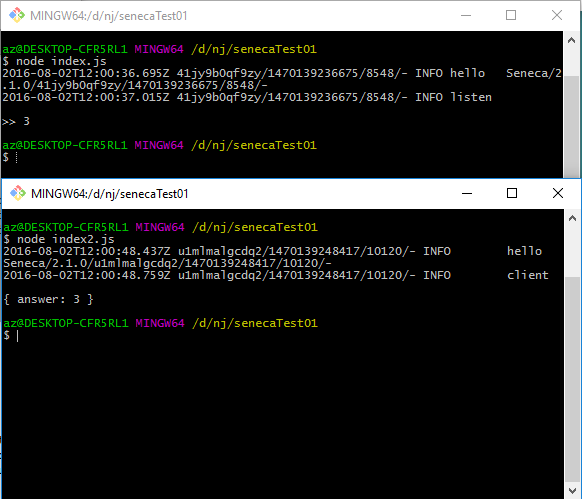
Si puň notare una stranezza: nella definizione del metodo abbiamo usato:
{role: 'math', cmd: 'sum'}Mentre per richiamarlo:
{role: 'math', cmd: 'sum', left: 1, right: 2}Anche se differente, come ha fatto seneca.js a riconoscerlo? Questo framework utilizza patrun (pattern-matching library) il cui autore č lo stesso di seneca.js. Patrun č in grado di riconoscere non solo i pattern uguali, ma anche quelli che assomigliano ed č in grado di valutare qualche si questi si avvicini di piů come somiglianza. Tornando agli esempi di definizione usati prima:
{class: 'math', method: 'sum'}
{class: 'math', method: 'avg'}Il pattern:
{role: 'math', cmd: 'sum', left: 1, right: 2}Avrŕ due similitudini su quattro con il primo pattern (definizione di "math" a "method") e solo una con la seconda (definizione di "math"), di conseguenza seneca.js userŕ il primo metodo.
Come detto, questo framework permette la comunicazione di processi sulla stessa macchina ma possiamo superare questo limite aggiungendo poche righe di configurazione:
var seneca = require('seneca')()
seneca.add({role: 'math', cmd: 'sum'}, function (msg, respond) {
var sum = msg.left + msg.right
console.log(">> "+sum);
respond(null, {answer: sum})
})
seneca.listen({
type: 'http',
port: '8000',
host: '192.168.0.4',
protocol: 'http'
});In listen ho aggiunto il tipo di connessione che seneca.js permetterŕ, specificando anche la porta e l'ip della macchina (192.168.0.4 č una VM sulla mia macchina di test). Il client, di conseguenza, subirŕ una modifica simile:
var seneca = require('seneca')()
seneca.client({
type: 'http',
port: '8000',
host: '192.168.0.4',
protocol: 'http'
});
seneca.act({role: 'math', cmd: 'sum', left: 1, right: 2}, function (err, result) {
if (err) return console.error(err)
console.log(result)
})Questa volta č definito in client dove andare a cercare il metodo, ed avviato il tutto, sulla seconda macchina la risposta.
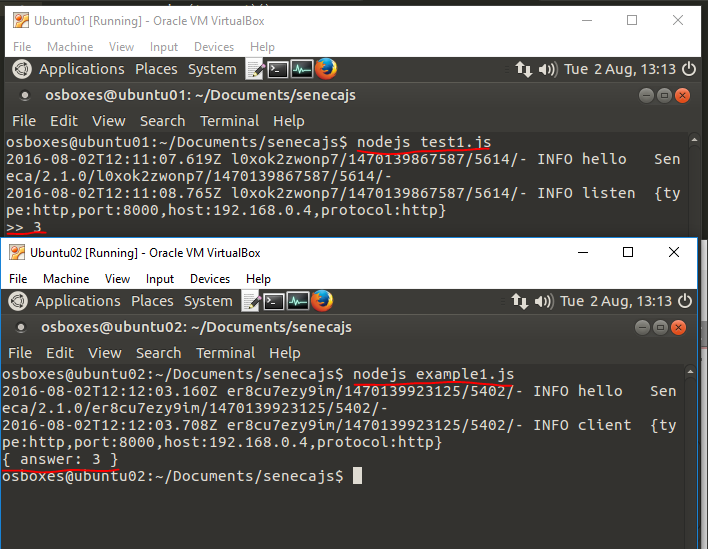
Fin qui tutto semplice e utile. Ma seneca.js ha un'altra feature molto comoda: si puň interfacciare con RabbitMQ. E' sufficiente installare un plugin con npm:
npm install seneca-amqp-transport
Ed ecco il codice che fornisce la funzione sum:
require('seneca')()
.use('seneca-amqp-transport')
.add({role: 'math', cmd: 'sum'}, function (msg, respond) {
var sum = msg.left + msg.right
console.log(">> "+sum);
respond(null, {answer: sum})
})
.listen({
type: 'amqp',
pin: 'role:math',
url: 'amqp://link_rabbitmq_service',
"exchange": {
"type": "topic",
"name": "seneca.topic",
"options": {
"durable": true,
"autoDelete": true
}
},
"queues": {
"action": {
"prefix": "seneca",
"separator": ".",
"options": {
"durable": true,
"autoDelete": true
}
},
"response": {
"prefix": "seneca.res",
"separator": ".",
"options": {
"autoDelete": true,
"exclusive": true
}
}
}
});E la versione client:
var client = require('seneca')()
.use('seneca-amqp-transport')
.client({
type: 'amqp',
pin: 'role:math',
url: 'amqp://link_rabbitmq_service',
"exchange": {
"type": "topic",
"name": "seneca.topic",
"options": {
"durable": true,
"autoDelete": true
}
}
});
client.act({role: 'math', cmd: 'sum', left: 1, right: 2}, function (err, result) {
if (err) return console.error(err)
console.log(result)
});La versione server presenta molti parametri per la configurazione della connessione a RabbitMQ e per i nomi che la queue e l'exchange avranno. Inoltre si deve porre attenzione alla definizione del parametro pin che dev'essere uguale a quello definitivo all'interno dell'add di seneca.js. Il bello di questo approccio, che potremo collegare un qualsiasi numero di processi server e client, e le richieste e la gestione di tutto sarŕ tranquillamente gestito e distribuito da RabbitMQ.
Ma... la direzione č corretta?
Questa č la domanda che mi sono posto dopo aver sviluppato alcuni miei processi/service. Per mia curiositŕ e perché lo trovo un'architettura molto interessante, sto rivolgendo la mia attenzione da parecchio tempo verso i microservices. Facendo mie prove personali e leggendo in giro materiale, mi sono ritrovato di fronte al dilemma della metodologia da utilizzare per il trasporto delle informazioni tra i vari service. La cura definitiva l'avevo trovata con i message broker come RabbitMQ, ma - ripeto - č la strada giusta? Se si segue meticolosamente l'architettura dei microservices... no. Perché un applicativo basato sui microservices sia effettivamente realizzato in modo ottimale NON ci deve essere nulla di centralizzato. Le decine/centinaia di microservices che svolgono le loro operazioni non dovrebbero dipendere da nessun servizio centralizzato: ogni processo puň essere spento e riavviato senza che la cosa si ripercuota sugli altri processi. E nel caso di RabbitMQ? Utilizzandolo stiamo centralizzando il sistema di messaggistica, e seguendo le regole architetturali dei microservices, questo č (relativamente) sbagliato - centralizzando il sistema di messaggistica rendiamo l'architettura sensibile al suo malfunzionamento (lasciando perdere la creazione di cluster di server dediti solo a RabbitMQ). Inoltre, questo me ne sono accorto per mia esperienza diretta, maggiore č la granularitŕ dei microservices e maggiore č l'utilizzo di messaggi e carico per il message broker. Se ci si pensa non č una cosa da poco visto che, finché si hanno service con maggiori responsabilitŕ (lasciate che usi questo termine) lo scambio di messaggi tra i vari service rimane contenuto, ma in un'archittetura prettamente microserices, il numero di messaggi scambiati sale vertiginosamente. E pensiamo solo a tutti i passaggi che essi comportano nel caso il service A richiede un semplice dato al service B:
- 1) Service A invia messaggio di richiesta al message Broker (prima richiesta via rete).
- 2) Il message broker riceve la richiesta, quindi invia l'ok della richiesta ricevuta al service A (seconda richiesta via rete).
- 3) Il message broker inserisce la richiesta nella queue dedicata e controlla che ci sia qualche processo remoto in grado di elaborare la richiesta. Appena trovato invia la richiesta al servizio B (terza richiesta via rete).
- 4) Il service B riceve la richiesta e comunica al message broker che č stata ricevuta (quarta richiesta via rete).
- 5) Il service B ha pronta la risposta, contatta il message broker inviando alla queue desiderata la risposta (quinta richiesta via rete).
- 6) Il message broker, ricevuta la risposta, comunica al service B che č arrivata (sesta richiesta via rete).
- 7) Il message broker invia al service A, grazie ad un'altra queue, la risposta (settima richiesta via rete).
- 8) Service A, finalmente, ha avuto la risposta e comunica al message broker che č tutto ok (ottava richiesta via rete).
Otto trasmissioni di dati via rete. E questa per ogni richiesta. E se fossero decine per ogni operazione di base della nostra procedura? Ipotizzando di voler mostrare una pagine web di un sito di e-commerce, potremo dividere tutte le operazioni, per generare la pagina, in questa sequenza di richieste a singoli service:
- 1) Richiesta info dell'utente attualmente autenticato (microservice users).
- 2) Richiesta elenco dei prodotti nel carrello (microservice user_products).
- 3) Richiesta elenco prodotti ricercati dall'utente (microservice products).
- 4) Richiesta disponibilitŕ dei singoli prodotti in magazzino (microservice warehouse).
- 5) Richiesta valutazioni dei prodotti (microservice rating).
- 6) Richiesta numero di commenti (microservice comments).
- 7) Richiesta banner dedicati (microservice banner).
- 8) Richiesta div per le news da visualizzare in un div a inizio pagina (microservice news).
- ...
Tralasciando la possibile suddivisione che ognuno di questi servizi potrebbe avere, usando questo minimo di richieste, avremo, come minimo, 64 trasmissioni in rete di informazioni tra i nostri sistemi e il message broker. Forse un po' dispendioso... c'č un altro modo? Sě, ed č pure banale: RESTful api. Innanzitutto sono semplici da creare sia nel mondo di node.js sia nel mondo di asp.net. Inoltre permettono la ricezione dei dati nel formato a noi piů congegnale (json o xml) e per essere richiamate e avere il risultato non hanno tutto il round trip visto prima: il service A richiama il service B attraverso una api rest, fine esecuzione. Semplice. Ma... come possiamo rendere il tutto scalabile? Su n server installiamo il nostro microservice che attende le richieste via http; come rendiamo questi service scalabili? La prima risposta che viene in mente, e come consigliato da un amico, č usare un load balancer (si puň usare nginx) che fa da gateway per il nostro service ed č in grado di bilanciare le richieste. Perfetto, problema risolto! Ne siamo sicuri? Ricapitolando: abbiamo escluso un message broker perché centralizzava la trasmissioni di messaggi, e vogliamo risolvere il problema con un altro servizio che centralizza la trasmissione dei dati (SM sta per microservices e LB per load balancer)?

Anche con un cluster di load balancer la situazione non cambierebbe. Dunque? Una possibile soluzione la si puň avere con l'uso dei service discovery. Il loro scopo č semplice: raccogliere, monitorare e rendere disponibili una porta unica di accesso per i servizi di cui abbiamo bisogno. Possiamo registrare le nostri api rest al loro interno, e chiunque potrŕ richiedere l'url per potervi accedere. Inoltre, un message broker, permette anche di controllare (in modo automatico o con script mirati) se ci sono problemi e in caso bloccare l'accesso alla api non funzionante/non accessibile. Nei miei studi ho preso come riferimento Consul. Questo service discovery mette a disposizione quanto detto sopra e molto altro (tra cui anche un'interfaccia web dove č possibile controllare lo stato di tutti i nostri servizi). Nel suo utilizzo piů semplice, possiamo comunicare con Consul via api rest per richiedere i servizi disponibili e quant'altro.
Dopo queste poche righe, si potrebbe avere lo stesso dubbio di prima: ma non č anche questo una strumento che centralizza il tutto visto che per sapere dove sono le api rest, dobbiamo chiedere a lui dove sono? Anzi peggio: se uso un servizio, ogni volta devo richiedere al service discovery quale url devo chiamare? Un round trip quasi peggiore di quello che avevamo con il message broker. Ma il bello sta proprio qui: un service discovery come Consul usa una strategia piů furba e molto interessante: semplificando, questo tool modifica il DNS della macchina in modo che quando chiamiamo un service, per la risoluzione del nome, interroghiamo anche Consul che ci indirizzerŕ al servizio attivo piů vicino e, se č disponibile piů di uno, bilancerŕ le richieste tra tutti i disponibili. L'approccio č proprio questo: su ogni macchina su cui vogliamo sfruttare questo servizio dobbiamo attivare Consul versione client, il quale comunicherŕ con uno o piů server dedicati che scambieranno informazioni sui servizi raggiungibili o meno. Il servizio di Consul č sě centralizzato, ma il vero lavoro lo fanno i servizi di service discovery sulle singole macchine. Ecco come saranno esposti e visibili i nostri service:

Qui di seguito, anche per mia nota personale, esporrň un esempio di configurazione su piů macchine di alcuni esempi di api rest scritte in node.js (il cui contenuto non č di alcun interesse: ritorna un banale messaggio e l'ip attuale della macchina su cui sta girando il processo) e di Consul. Userň delle virtual machine con linux; solo alla fine tratterň anche Windows perché merita una spiegazione a parte. Innanzitutto, nel mio caso ho 3 VM con questi IP:
192.168.0.4 192.168.0.5 192.168.0.6
Sulla 192.168.0.4 installerň il server principale di Consul piů un service in node.js; sulla 192.168.0.5 installerň Consul come client e anche qui avrŕ un service in node.js uguale al precedente (per simulare un load balancing), e sull'ultima macchina installerň solo Consul perché possa richiamare il service dalle due macchine. Per dettagli tecnici rimando il link ufficiale https://www.consul.io/.
192.168.0.4: iniziamo creando in file di configurazione dove inserirň la definizione del mio service in node.js:
{
"services": [
{
"id":"web1",
"name": "web",
"tags": ["xxx"],
"address": "192.168.0.4",
"port": 1337,
"enableTagOverride": false
}
]
}L'id č univoco perché definisce il nome del servizio nel dettaglio (possiamo inserire nella lista tutti i service che vogliamo) e name, invece, definisce il nome e se questo viene utilizzato anche su altre macchine, viene usato per creare i servizi simili che vogliamo mettere sotto load balancer. Il tag in questo caso č inutile, l'address specifica l'ip della macchina (attuale in questo caso) raggiungibile dalle altre macchine (qui ritornerň a breve). Port č la porta cui il nostro servizio risponde e l'ultimo parametro lavora in copia con tags e, come scritto sopra, per ora non ci serve.
Fine, ora salviamo questo file in /etc/consul.d/web.json (possiamo inserirlo dove vogliamo, la documentazione consiglia qui anche perché č la directory dove solitamente vengono installati i servizi). Quindi scaricato l'eseguibile, lo possiamo avviare da terminale in questo modo:
consul agent -server -bootstrap-expect 1 -data-dir /tmp/consul -node=agent-one -bind=192.168.0.4 -config-dir /etc/consul.d
Come parametro specifichiamo che č la versione server che vogliamo utilizzare, quindi le directory dove salverŕ i suoi dati, il nome (agent) e il file di configurazione dei servizi prima definito. Avviato, nel terminale apparirŕ una lunga sequenza di operazioni e se non ci sono errori il tutto si bloccherŕ lě.
Come scritto prima, Consul si interfaccia direttamente con il DNS della macchina. Nel caso della VM si tratta di dnsmasq (possiamo usare anche Bind). Aggiungiamo anche il file 10-consul (come da documentazione) in /etc/dnsmasq con questo contenuto:
# Enable forward lookup of the 'consul' domain: server=/consul/127.0.0.1#8600
Questo comunica al DNS della macchina che dovrŕ fare il forward delle richieste anche a Consul. Ok, abbiamo finito. Passiamo alla seconda macchina all'ip 192.168.0.5. Il DNS dev'essere configurato anche qui come abbiamo appena visto. Creiamo il file web.json come prima ma con questo contenuto:
{
"services": [
{
"id":<b>"web2"</b>,
"name": "web",
"tags": ["xxx"],
"address": <b>"192.168.0.5"</b>,
"port": 1337,
"enableTagOverride": false
}
]
}Notare l'ip differente e l'id. Avviamo Consul con questo comando:
consul agent -data-dir /tmp/consul -node=agent-two -bind=192.168.0.5 -config-dir /etc/consul.d
Il terminale visualizzerŕ varie informazioni ma l'ultima riga sarŕ un errore perché non potrŕ connettersi al servizio Consul principale. Dobbiamo in qualche modo fare il join di questa macchina, e lo facciamo dalla macchina 192.168.0.4 con questo comando:
consul join 192.168.0.5
Immediatamente, la seconda macchina visualizzerŕ un messaggio di effettivo collegamento.
Passando all'ultima macchina, 192.168.0.6, si fanno tutti i passaggi come nella macchina precedente, tranne la scrittura del file web.json perché questa macchina non esporrŕ nessun servizio ma li utilizzerŕ. Il comando per avviare Consul sarŕ come il precedente ma senza la definizione del file di configurazione:
consul agent -data-dir /tmp/consul -node=agent-three -bind=192.168.0.6
Dalla macchina 192.168.0.4:
consul join 192.168.0.5
E sempre da questa, da terminale, scriviamo: consul members per avere questo risultato:

Ok, abbiamo finito, ma a quale nome risponderŕ il nostro servizio? Di base Consul creerŕ il tutto sotto il dominio .service.consul (č personalizzabile). Avendo definito nel file web.json il nome "web", dal terzo browser potremo richiamare via browser o da terminale con curl, questo url:
http://web.service.consul:1337
Ora dalla terza macchina, 192.168.0.6, possiamo verificare lo stato dei servizi con un link:
curl web.service.consul:1337
Ecco un esempio di output:
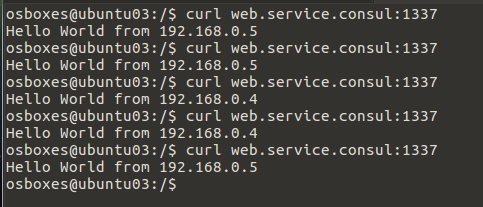
Se richiamiamo questo link da una macchina con lo stesso servizio, sarŕ sempre eseguito quello sulla stessa macchina e solo se questo sarŕ fermato, Consul invierŕ la richiesta su una macchina esterna.
Nella definizione del servizio nel file web.json avevo scritto che si doveva specificare l'ip della macchina in rete perché, se avessi definito in questo modo:
{
"services": [
{
"id":"web1",
"name": "web",
"tags": ["xxx"],
"address": "127.0.0.1",
"port": 1337,
"enableTagOverride": false
}
]
}Una macchina esterna, alla risoluzione del nome "web.service.consul", sarebbe stato inviato all'ip 127.0.0.1 con le conseguenze facilmente intuibile (l'ho voluto specificare perché era stata una mia disattenzione iniziale).
Ora passiamo al mondo Windows. Per unire la nostra macchina windows a Consul con un mia api rest, ho scritto:
consul agent -data-dir ./tmp/consul -node=agent-windows -bind=192.168.0.2 -config-dir ./services
Consul funziona anche su questo sistema operativo, e in effetti io avevo creato con asp.net core una api rest esposta con kestrel, che veniva chiamata e trovata senza problemi da Consul (richiamando l'url http://web.service.consul veniva messa in load balancing anche l'api su windows), ma il problema č come fare il forward lookup del DNS di windows in modo che anche esso possa risolvere il nome dei nostri servizi in Consul. Il problema č che si deve installare un servizio DNS sulla macchina e poi configurarlo, ma qui mi sono scontrato contro dei miei limiti di configurazione e il tempo era quello che era - č estate pure per me!
Quanto ho scritto? Troppo, lo so. Conclusioni? Dico quello che penso io per quanto puň valere - questo č il mio blog dove posso scrivere ciň che mi va, no? Innanzitutto se si sposa il mondo dei microservices si possono affrontare e utilizzare qualsiasi infrastruttura vogliamo: vogliamo usare un message broker? Vogliamo usare un service discovery? Non ho mai negato che il mondo dei message broker (con RabbitMQ per esempio) mi č sempre piaciuto (e non ci avrei dedicato due post su questo blog se fosse l'opposto). Da qualche tempo, dopo i primi dubbi, sto affrontando il mondo dei service discovery, e dopo le primi titubanze mi sta convincendo sempre piů. Da quando ho provato a scrivere codice utilizzando questo mondo, mi sono ritrovato molto a piů agio scrivendo api rest che chiamate ad un message broker. Il codice č piů semplice, č meglio testabile (si puň testare velocemente un service anche da browser). Studiando in contemporanea altre novitŕ come asp.net core, infine, mi sono ritrovato con kestrel che sembra fatto apposta per aprire l'asp.net al mondo dei microservice (č banale creare una api rest e lanciare una istanza di kestrel che rimarrŕ in attesa delle richieste, senza scomodare IIS, mini IIS, o simil web server). Creando un nuovo progetto in Visual Studio utilizzando lo scheletro creato per le web api, č sufficiente modificare in program.cs il codice seguente:
public static void Main(string[] args)
{
var host = new WebHostBuilder()
.UseKestrel()
.UseContentRoot(Directory.GetCurrentDirectory())
.UseUrls("http://*:1337")
.UseStartup<Startup>()
.Build();
host.Run();
}Ed ecco il service bello disponibile per il nostra applicazione basata su microservice. Posso dirlo? Mi aggrada.

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
- Docker Swarm e constraint in un mondo reale, il 29 dicembre 2016 alle 18:04
- Docker + Consul + Registrator, il 23 dicembre 2016 alle 14:48
- AMD/UMD in javascript, tanto per ricordarmi, il 15 dicembre 2016 alle 18:54
- Asp.net Core, Docker e Docker Swarm, il 5 dicembre 2016 alle 19:02
- Cross apply con i campi XML, il 10 luglio 2009 alle 09:22