
Divide et impera con c# e un message broker
Questo lo voglio condividere. Qualche tempo fa si discuteva sul semplice paradigma informatico divide et impera e il suo approccio reale. Di base non si basa su niente di difficile: avendo un compito X per risolverlo lo si suddivide in compiti piů piccoli, e questi in piů piccoli ancora e cosě via, in modo ricorsivo. Un esempio reale che usa questo paradigma č il famoso quicksort che, preso un valore medio, detto pivot, al primo passaggio suddivide gli elementi dell'array da ordinare a sinistra se piů piccoli del pivot, a destra se piů grandi. Dopodiché, questi due sotto array, sono ancora suddivisi, il primo con un suo valore medio, il secondo con un altro valore medio; quindi si ricomincia a la suddivisione spostando gli elementi da una parte all'altra a seconda del valore del pivot: alla fine di questo passaggio saranno quattro gli array. Se l'ordinamento non č completo, si dividono ancora questi quattro array in otto piů piccoli, ognuno con il suo pivot medio e con il dovuto spostamento da una parte o dall'altra... cosě fino a quando l'array č ordinato (maggiori info alla pagina di wikipedia dove č presente anche in modo grafico tale algoritmo).Prendendo il codice di esempio dalla pagina di Wikipedia, posso costruire la versione in C#:
static List<int> QuickSortSync(List<int> toOrder)
{
if (toOrder.Count <= 1)
{
return toOrder;
}
int pivot_index = toOrder.Count / 2;
int pivot_value = toOrder[pivot_index];
var less = new List<int>();
var greater = new List<int>();
for (int i = 0; i < toOrder.Count; i++)
{
if (i == pivot_index)
{
continue;
}
if (toOrder[i] < pivot_value)
{
less.Add(toOrder[i]);
}
else
{
greater.Add(toOrder[i]);
}
}
var lessOrdered = QuickSortSync(less);
var greaterOrdered = QuickSortSync(greater);
var result = new List<int>();
result.AddRange(lessOrdered);
result.Add(pivot_value);
result.AddRange(greaterOrdered);
return result;
}
Anche se non č ottimizzata, non importa per lo scopo finale di questo post: il suo sporco lavoro lo fa ed č quanto basta. Eseguito, si potrŕ vedere l'array di numeri interi prima e dopo l'ordinamento:
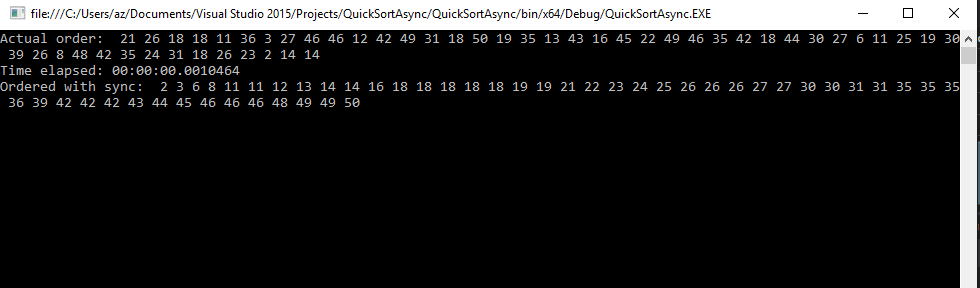
Per migliorare tale versione potremmo utilizzare chiamate asincrone e piů thread: in fondo giŕ la prima suddivisione prima spiegata con due parole, che ritorna due array, puň essere elaborata con due thread separati, ognuno che elabora il suo sotto-array. E alla divisione successiva, potremo utilizzare altri thread. Avendo a disposizione un microprocessore con piů core, avremo immediatamente vantaggi prestazionali non indifferenti se confrontati con la versione mono-thread prima esposta. Per un approccio multithread ho parlato giŕ in modo esteso in questo mio altro post, e in questo portale potete trovare molte altre informazioni. Ovviamente sempre la cura per ogni male la possibilitŕ di utilizzare tutti i core della propria macchina e una moltitudine di thread paralleli. Ma fino a quando si puň estendere oltre questi limiti? I thread non sono infiniti cosě come i core di una cpu. Spesso alcuni novizi - lasciatemi passare tale termine - pensano che l'elaborazione parallela sia la panacea per tutti i problemi. Ho molte operazioni da svolgere in parallelo, come posso risolverle da programmazione? Semplice, una marea di thread paralleli - e prima del Framework.Net 4 e dei suoi Task e dell'async/await del Framework 4.5 - sembrava una delle tecniche piů facili da utilizzare e forse anche piů abusate. Alla prima lettura, spesso il neofito, alla seguente domanda sbaglia:
Ipotizzando di avere una cpu monocore (per semplificare), e dovendo eseguire N operazioni un nostro programma ci mette esattamente 40 secondi. Se questo programma lo modificassi per potere usare 4 thread paralleli, quanto tempo ci metterebbe questa volta ad eseguire tutta la mole di calcoli?
Se si risponde in modo affrettato, si potrebbe dire 10 secondi. Se sapete come funziona una cpu e i suoi core e non vi siete fatti ingannare dalla domanda, avrete risposto nel modo corretto: ~40 secondi! La potenza di calcolo di una cpu č sempre quella e non č suddividendola in piů thread che si ottengono miracoli. Solo con 4 core avremo l'elaborazione conclusa in 10 secondi.
Ma perché questa divagazione? Perché se dovessimo estendere il paradigma Divede et impera ulteriormente al programmino di ordinamento qui sopra perché potesse superare, teoricamente, le limitazioni della macchina (cpu e memoria), quale strada si potrebbe - ripeto - si potrebbe intraprendere? La soluzione č facilmente intuibile: aggiungiamo un'altra macchina per la suddivisione di questo processo; non basta ancora? Possiamo aggiungere tutte le macchine e la potenza necessaria per l'elaborazione.
Per risolvere questi tipi di problemi e per poter poi avere la possibilitŕ di estendere in modo pressoché infinito un progetto, la suddivisione di un nostro processo in microservice č una delle soluzioni piů gettonate, cosě come conoscere il famoso scale cube di Martin L. Abbott e Michael T. Fisher.

Mettendo da parte il programmino prima scritto per il sort ed estendendo il disco ad applicativi di un certo peso, possiamo definire una piccola web application che funge da blog: visualizzazione dell'elenco dei post, il singolo dettaglio, un'eventuale ricerca e l'utilizzo dei tag. Di base, avremo un database dove salvare i post, quindi una web application con i classici 3 layer per la presentazione, la business logic e il layer per il recupero dei dati. Questo tipo di applicazione, nel cubo, starebbe nel vertice in basso a sinistra. Si tratta di una applicazione monolitica, dove tutte le funzioni sono racchiuse all'interno di un singolo processo. Se volessimo spostarci lungo l'asse X, dovremmo duplicare questa web application su piů processi e server. I vantaggi sarebbero subito evidenti: in caso questa applicazione avesse successo e le dotazioni hardware della macchina su cui gira non fossero piů sufficienti, l'installazione dello stesso su piů server risolverebbe l'aumento di carico di lavoro (tralasciando il potenziamento del database). L'asse Y del cubo č quello piů interessante: con esso spostiamo le varie funzioni della web application in piccoli moduli indipendenti. Sempre tenendo come esempio il blog, potremmo usare il layer di presentazione sul web server, ma i layer della busines logic suddividerla in piů moduli indipendenti; il primo layer, in questo modo, interrogherŕ questo modulo o altri per richiedere la lista di post e, appena ricevuta la risposta, ritornerŕ al client i dati richiesti. Solo per questo punto si puň notare un notevole vantaggio: in un mondo informatico sempre piů votato all'event driver e all'asincrono - basti notare il notevole successo di Node.js verso cui si stanno spostando pressoché tutti in modo piů o meno semplificato, async/await fa parte ormai della quotidianitŕ del programmatore .net - dove nulla dev'essere sprecato e nessun thread deve rimanere in attesa, questo approccio permette il carico ottimale dei server. Sono in vena di quiz, cosa c'č di "sbagliato" (notare le virgolette) nel codice seguente (in c#)?
var posts = BizEntity.GetPostList(); var tags = BizEntity.GetTagList();
Cavolo, sono due righe di codice, che cosa potrebbero avere mai di sbagliato? Ipoteticamente la prima prende dal database la lista dei post di un blog, mentre la seconda la lista dei tag (questo codice potrebbe essere utile per la web application vista prima). La prima lista č usata per visualizzare il lungo elenco di post del nostro blog, la seconda lista per mostrare i tag utilizzati. Se avete spostato ormai la vostra mentalitŕ nella programmazione del vostro codice in modo asincrono o se usate node.js, avrete giŕ capito che cosa c'č di sbagliato in queste due righe di codice: semplicemente esegue due richieste in modo sequenziale! Il thread arriva alla prima riga di codice e qui rimane bloccato in attesa della risposta del database; avuta la risposta, esegue una seconda richiesta e rimane ancora in attesa. Piuttosto, perché non lanciare entrambe le richieste in parallelo e liberare il thread in attesa della risposta? In C#:
var taskPost = BizEntity.GetPostListAsync();
var taskTag = BizEntity.GetTagListAsync();
Task.WaitAll(new Task[] {taskPost, taskTag});
var posts = taskPost.Result;
var tags = taskTag.Result;Ottimo, questo č quello che volevamo: esecuzione parallela e thread liberi per processare altre richieste.
Ritorniamo all'esempio del blog: ipotizziamo a questo punto di voler aggiungere la possibilitŕ di commentare i vari post del nostro blog. Nel caso dell'applicazione monolitica all'inizio esposta, dovremo mettere mano al codice dell'intero progetto, mentre con la suddivisione in moduli indipendenti piů piccoli, appunto microservice, dovremo scrivere un modulo indipendente da installare su uno o piů server (si ricordi l'asse X), quindi collegare gli altri moduli che richiedono questi dati. Infine l'asse Z si ha una nuova differenziazione, possiamo partizionare i dati e le funzioni in modo che le richieste possano essere suddivise, per esempio, per l'anno o il mese di uscita del post, o se fanno parte di certe categorie e cosě via... Non si penserŕ che tutte le pagine archiviate e su cui fa la ricerca Google, sono su un solo server replicato, vero?
Spiegato in teoria il famoso scale cube (con i miei limiti), non ci rimane che rispondere all'ultima domanda: chi č il collante tra tutti questi micro service? Il framework.net mette a disposizione una buona tecnologia per permettere la comunicazione tra processi che siano sulla stessa macchina o su una batteria di server in una farm factory, o che siano in remoto e comunichino con internet. Utilizzando WCF si puň passare facilmente tra i web service WSDL standard a comunicazioni piů veloci via tcp e cosě via. Questo approccio ci pone di fronte ad un evidente limite essendo queste comunicazioni dirette: ipotizzando di avere una macchina con il layer di presentazione del blog, per richiedere i post al microservice che gira su un secondo server, deve sapere innanzitutto DOVE si trova (ip address) e COME comunicare con esso. Risolto questo problema in modo semplice (salvando nel web.config, per esempio, l'ip della seconda macchina e usando un'interfaccia comune per la comunicazione) ci troviamo di fronte immediatamente ad un altro problema: come possiamo spostarci lungo l'asse X del cubo inserendo altre macchine con lo stesso microservice in modo che le richieste vengano bilanciate automaticamente? Dovremo fare in modo che il chiamante sia aggiornato continuamente sul numero di macchine con il servizio di cui ha bisogno, con eventuali notifiche di anomalie volute o no: manutenzione del server con la messa offline del servizio, oppure una rottura improvvisa della macchina. Per l'esempio qui sopra, il layer di presentazione dovrebbe avere al suo interno anche la logica di gestione di tutto questo... e cosě ogni microservice della nostra applicazione... Assolutamente troppo complicato e ingestibile. Perché dunque non delegare questo compito ad un componente esterno come un message broker?
Azure mette a disposizione il suo Microsoft Azure Service Bus, molto efficiente e ottimale nel caso di utilizzo del cloud di Microsoft; nel mio caso le mie preferenze vanno per RabbitMQ, anche perché č l'unico su cui ho lavorato in modo approfondito. Innanzitutto RabbitMQ č un message broker open source completo che permette ogni tipo di protocollo (da AMPQ https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol a STOMP https://en.wikipedia.org/wiki/Streaming_Text_Oriented_Messaging_Protocol) e, soprattutto, possiede client per quasi tutte le tecnologie, dal framework .net, passando per Java, per nodejs e cosě via. Inoltre č possibile installarlo come server sui sistemi operativi principali: Windows, Linux ad Apple. Se per fare delle prove non si vuole installare nulla sulla propria macchina di sviluppo ci si puň affidare ad alcuni servizi gratuiti (e limitati) disponibili in internet. Attualmente CloudAMPQ (https://www.cloudamqp.com/) mette a disposizione tra i pacchetti anche la versione free con un limite di 1.000.000 di messaggi al mese):
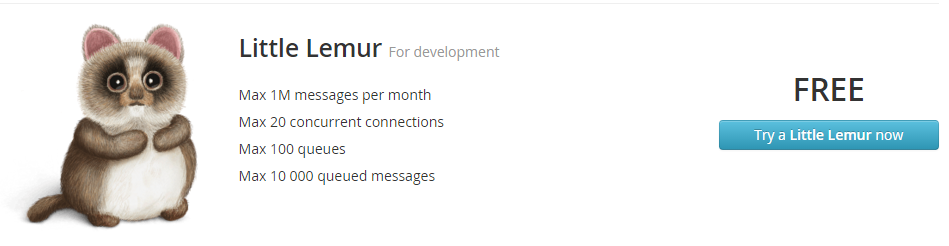
Per esigenze di altissimo livello sono disponibili anche piani da centinaia di migliaia di messaggi al secondo in cluster, ma per dei semplici test va piů che bene la versione free. Una volta registrati si avrŕ a disposizione un servizio RabbitMQ completo con tutti i parametri di accesso anche via API Rest sia da classica pagina web:
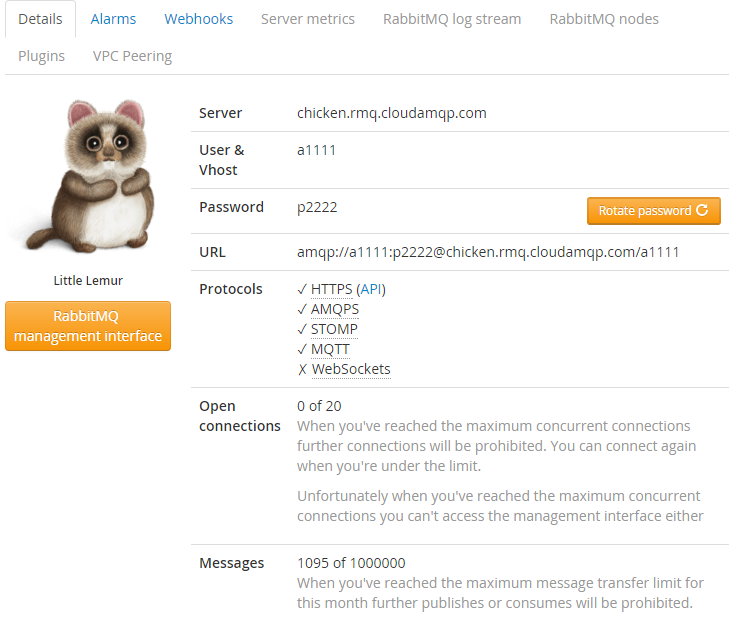
(User e password non sono reali in questo caso.)
Cliccando sul pulsante arancio "RabbitMQ management interface", si avrŕ a disposizione il pannello di controllo completo per eventuali configurazioni, come la creazione di code (Queue) e delle exchange (eventuali perché il tutto č possibile anche da codice):
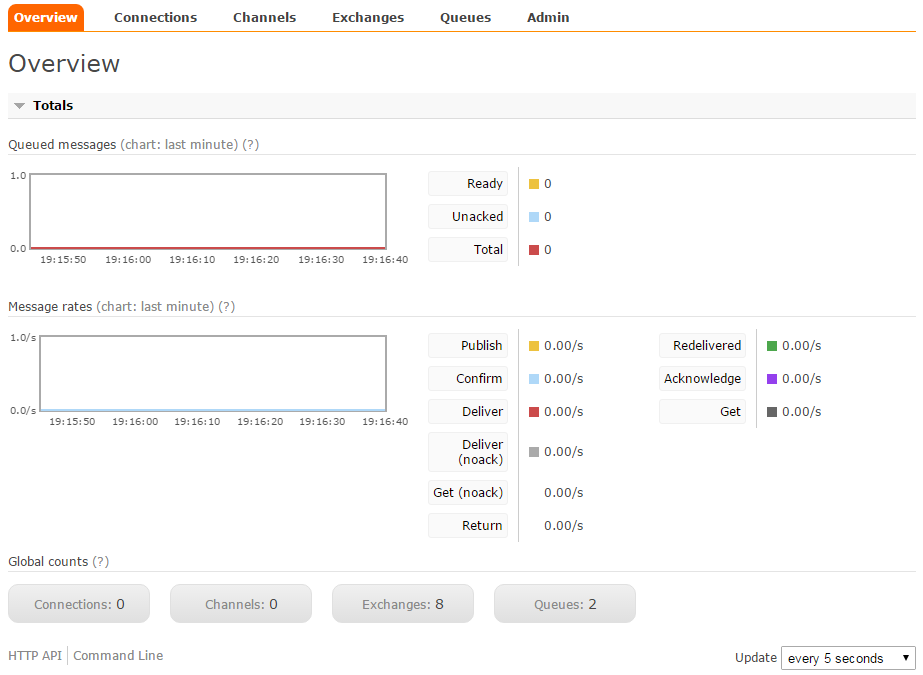
Se non si vuole usare un servizio pubblico si puň scaricare direttamente dal sito di RabbitMQ la versione adatta al proprio sistema operativo:
Per la versione Windows ho riscontrato in tutte le occasioni che l'ho dovuto installare un problema di avvio del servizio. Per verificare che tutto funzioni č sufficiente andare nel menu start e, dopo aver selezionato la voce: "RabbitMQ Command Prompt", scrivere il comando:
rabbitmqctl.bat status
Se la risposta č un lungo JSON vuol dire che č tutto corretto, altrimenti si noteranno errori di avvio del nodo di RabbitMQ e roba simile. In questi casi il primo passo č controllare il contenuto dei cookie creati da Erlang (da installare insieme a RabbitMQ), il primo č nel path:
%HOMEDRIVE%%HOMEPATH%\.erlang
Il secondo:
C:\Windows\.erlang.cookie
Se sono uguali e il problema sussiste, da terminale precedente avviato in modalitŕ amministratore, avviare questi tre comandi di seguito:
rabbitmq-service remove rabbitmq-service install net start rabbitmq
Se anche questo non funziona, non resta che affidarsi a San Google. Se vogliamo che nella versione installata in locale sia disponibile l'interfaccia web, si devono utilizzare questi comandi:
rabbitmq-plugins enable rabbitmq_management rabbitmqctl stop rabbitmq-service start
Ora sarŕ possibile aprire un browser e aprire l'interfaccia web con:
Username: guest, password: guest.
Ora, sia che si sia utilizzato un servizio free in internet, sia che si sia installato il tutto sulla propria macchina, per una semplice prova si puň andare nel tab Queues e creare una nuova Queue su cui si potranno inserire e leggere messaggi direttamente da questa interfaccia. Ok, ma cosa sono le code e le exchange? In rabbitMQ (e in qualsiasi altro broker message) ci sono tre componenti principali:
- L'exchange che riceve i messaggi e li indirizza a una coda (queue); questo componente č facoltativo.
- Queue, č la coda vera e propria dove sono salvati i messaggi.
- Il binding che lega una exchange a una coda.
Come detto prima, creando una coda, poi č possibile inserire e leggere i messaggi inseriti da codice. Tutto qua. Niente di complicato. Una coda puň avere piů proprietŕ, le principali:
- Durata: possiamo fare in modo che RabbitMQ salvi i messaggi sul disco, in modo che, in caso di riavvio della macchina, la coda eventualmente in attesa di elaborazione non vada persa.
- Auto cancellazione: č possibile fare in modo che una coda, appena tutte le connessioni collegate sono chiuse, venga automaticamente cancellata.
- Privata: una coda accetta come lettore della coda un solo processo; ma chiunque puň aggiungere elementi al suo interno.
Come scritto sopra, da codice possiamo connetterci direttamente con una coda, inviare messaggi e altri processi prelevarli ed eventualmente elaborarli. La vera forza dei message broker non si ferma qui ovviamente. L'uso dell'exchange ci permette di scrivere regole per la consegna del messaggi nelle code collegate dal relativo binding. Abbiamo a disposizione tre modi di invio con l'exchenge:
- Direct: inserendo la routing key diretta il nostro messaggio sarŕ inviato a quella e solo quella coda collegata all'exchange con quel binding come nella figura sottostante:
- Topic: č possibile inserire dei caratteri jolly nella definizione della routing key in modo che un messaggio sia inviato a una o piů code che rispettano questo topic. Semplice esempio: un exchange puň essere collegato a piů queue; nel caso fossero due, prima con entrambe la routing key: #.message, inviando un messaggio in modalitŕ topic con una di queste routing key: a1.message, qwerty.message, entrambe le code riceverebbero il messaggio.
- Header exchange: invece della routing key vengono controllati i campi header del messaggio.
- Fanout: tutte le code collegate ricevono il messaggio.
Un altro dettaglio da non sottovalutare nell'utilizzo dei message broker č la sicurezza della consegna e della ricezione dei messaggi. Se un log perso puň essere di minore importanza e sopportabile (causa il riavvio della macchina o una qualsiasi causa esterna), la perdita di una transazione per una prenotazione o pagamento comporta gravi problemi. RabbitMQ supporta l'acknowledgement message: in questo modo RabbitMQ invia il messaggio a un nostro processo che lo elabora, ma non lo cancella dalla coda finoaché il processo non gli invia un comando per la cancellazione. Se, durante, questo processo muore e cade la connessione tra lui e il message broker, questo messaggio sarŕ inviato al prossimo processo disponibile.
Per fare una semplice prova da interfaccia, andando nella sezione "Queues" e creiamo una nuova coda dal nome "TestQueue":
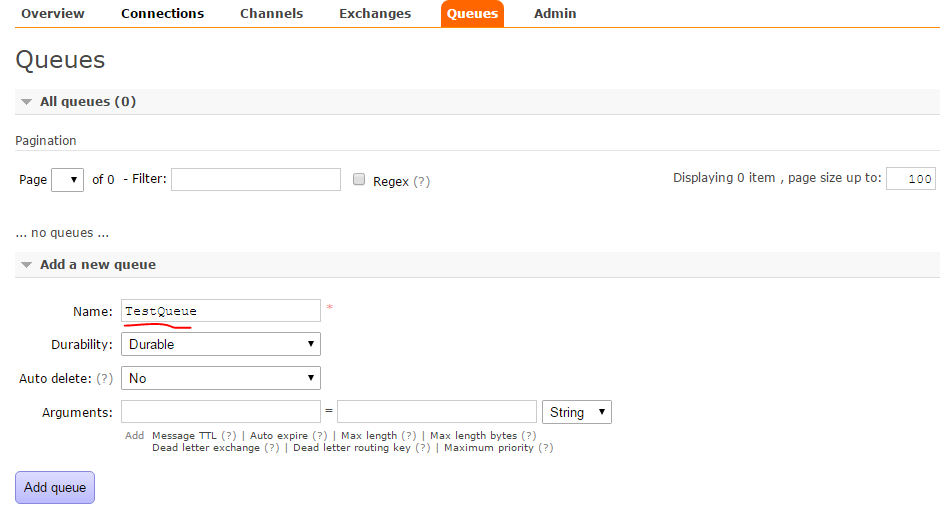
Cliccando su "Add queue" la nostra nuova coda apparirŕ nella lista della pagina. Si possono anche modificare la durata e le altre proprietŕ della queue prima citate, ma si puň lasciare tutto cosě com'č e andare avanti. Creiamo ora una exchange dalla sezione "Exchanges" dal nome "ExchangeTest" e il type in "Direct":
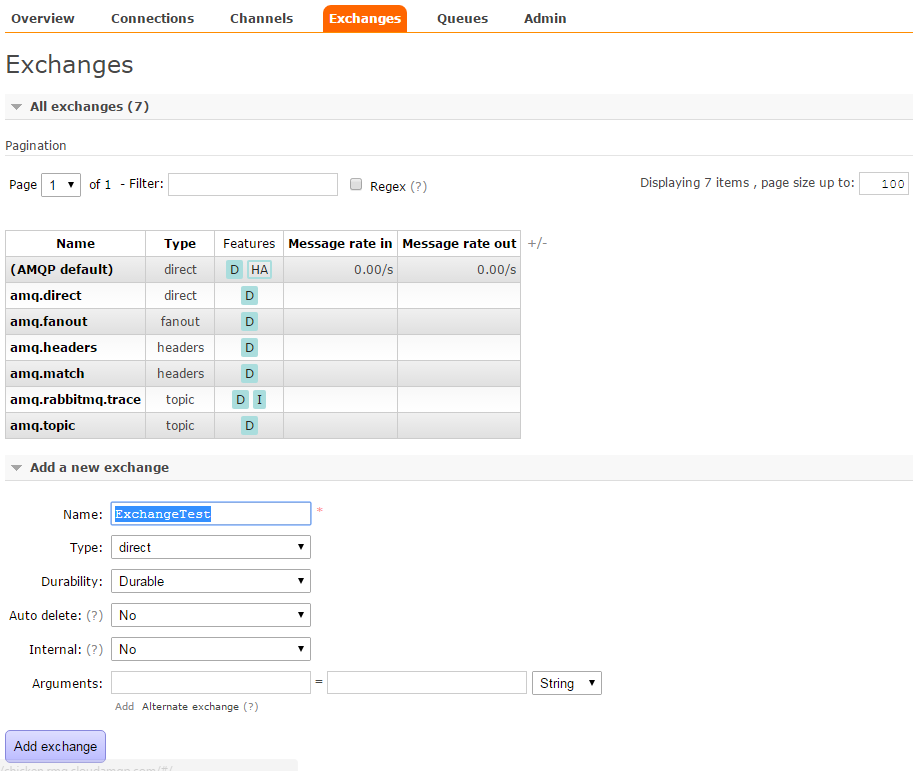
E ora colleghiamo l'exchange e la queue prima creata. Nella tabella della stessa pagina si noterŕ che č apparsa la nostra Exchange. Cliccandoci sopra abbiamo ora la possibilitŕ di definire in binding:
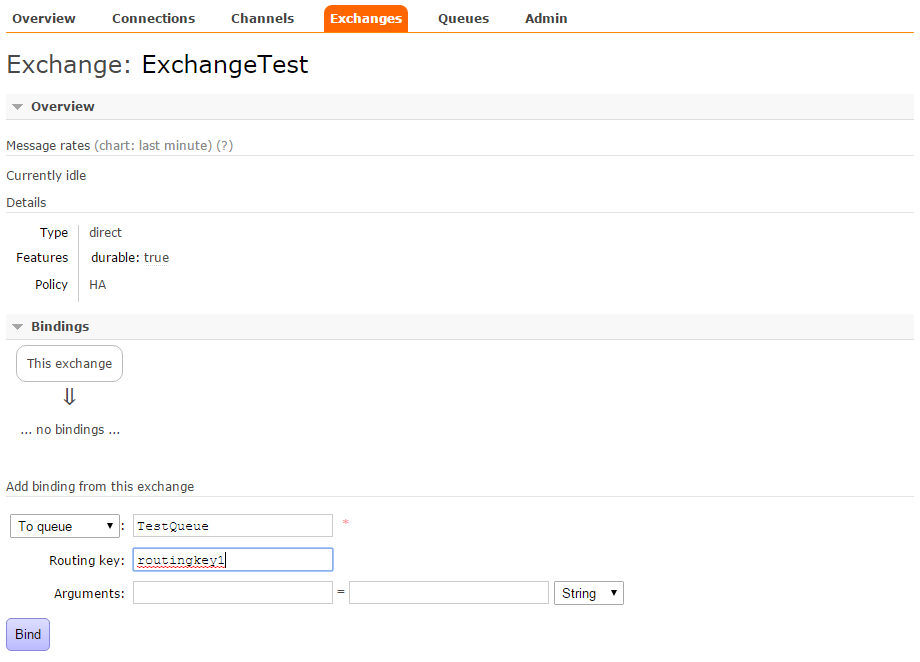
Se č tutto corretto, vedremo una nuova immagine che mostra il collegamento.
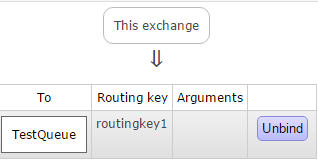
Ora nella stessa pagina aprire la sezione "Publish message" e inserire la routing key prima definita e del testo di prova. Quindi cliccare su "Publish message":
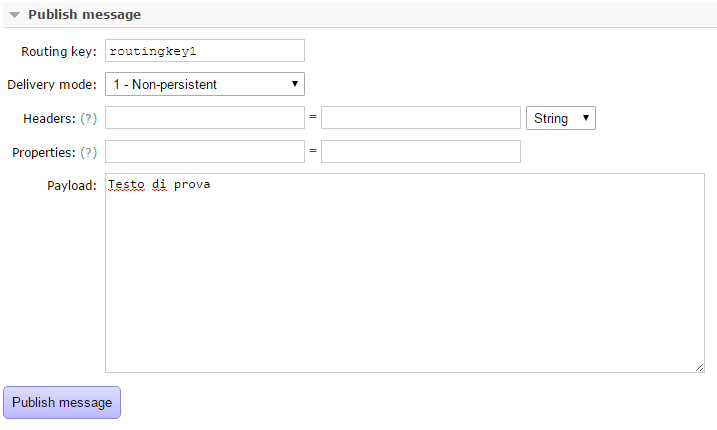
Se tutto č andato bene, apparirŕ un messaggio su sfondo verde che avvisa che il messaggio č stato inviato alla queue correttamente. Per verificare andare nella sezione "Queues" e si vedrŕ che ora la coda avrŕ un messaggio:
Andando nella parte inferiore della pagina in "Get Message" sarŕ possibile leggere e cancellare il messaggio.
Ok, tutto semplice e bello... ma se volessi farlo da codice? Di base il modo di comunicazione piů semplice č la one-way. In questo caso un processo invierŕ un messaggio ad una queue e un altro processo leggerŕ tale messaggio (nel progetto in allegato sono i progetti Test1A e Test1B). Innanzitutto č necessario aggiungere il reference alla libreria RabbitMQ.Client, disponibile in Nuget. Quindi ecco il codice che aspetta i messaggi alla queue (il codice crea automaticamente la queue Example1 e nella soluzione il cui link si trova a fine di questo post, ha come nome Example1A il progetto), innanzitutto il codice per la lettura e svuotamento della coda:
const string QueueName = "Example1";
static void Main(string[] args)
{
var connectionFactory = new ConnectionFactory();
connectionFactory.HostName = "localhost";
using (var Connection = connectionFactory.CreateConnection())
{
var ModelCentralized = Connection.CreateModel();
ModelCentralized.QueueDeclare(QueueName, false, true, false, null);
QueueingBasicConsumer consumer = new QueueingBasicConsumer(ModelCentralized);
string consumerTag = ModelCentralized.BasicConsume(QueueName, true, consumer);
Console.WriteLine("Wait incoming message...");
while (true)
{
var e = (RabbitMQ.Client.Events.BasicDeliverEventArgs)consumer.Queue.Dequeue();
string content = Encoding.Default.GetString(e.Body);
Console.WriteLine("> {0}", content);
if (content == "10")
{
break;
}
}
}
}ConnectionFactory ci permette di creare la connessione al nostro server di RabbitMQ (in questo esempio con localhost, l'username e password guest sono utilizzate automaticamente). In questo caso in ModelCentralized č specificato il nome della queue, i tre valori boolean successivi servono per specificare se essa č durable (i messaggi sono salvati su disco e recuperati in caso di riavvio), exclusive (solo chi crea la queue puň leggerne il contenuto) e autoDelete (la queue si cancella quando anche l'ultima connessione ad essa viene chiusa). Alla fine l'oggetto consumer con la funzione Dequeue interrompe il thread del processo e rimane in attesa del contenuto della queue; all'arrivo del primo messaggio ne prende il contenuto (questa dll per il framework.net ritorna un array di byte) e trasformato in stringa lo visualizza a schermo.
Il codice per l'invio (Example1B):
// Tralasciato il codice uguale all'esempio precedente
// fino all'istanza di ModelCentralized:
var ModelCentralized = Connection.CreateModel();
Console.WriteLine("Send messages...");
IBasicProperties basicProperties = ModelCentralized.CreateBasicProperties();
byte[] msgRaw;
for (int i = 0; i < 11; i++)
{
msgRaw = Encoding.Default.GetBytes(i.ToString());
ModelCentralized.BasicPublish("", QueueName, basicProperties, msgRaw);
}
}
Console.Write("Enter to exit... ");
Console.ReadLine();
}Il resto del codice sono istanze ad oggetti necessari all'invio dei messaggi (senza impostare alcune proprietŕ particolare) e trasformato il nostro messaggio in un array di bytes, grazie alla funzione BasicPublish viene inviato effettivamente alla queue QueueName (il primo parametro con una stringa vuota, č il nome dell'eventuale exchange utilizzato; in questo caso inviando il messaggio direttamente alla queue non c'č bisogno dell'exchange). Il codice invia una sequenza di numeri alla coda, e se dopo l'avvio si controlla nell'applicazione web prima vista, si vedrŕ che la queue "Example1" contiene 11 messaggi.
Il risultato:
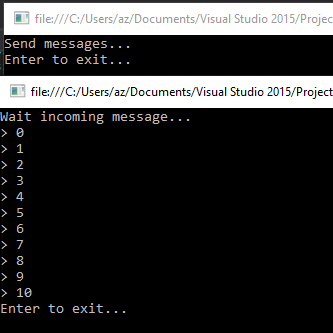
Introduciamo l'uso dell'exchange con l'invio dei messaggi con una queue privata. Inoltre impostiamo la coda in modo che siamo noi a inviare l'acknowledgement message. Il codice si complica di poco per la console application in attesa dei messaggi (Example2A).
// Si definisce il nome dell'exchange:
const string ExchangeName = "ExchangeExample2";
// Il nome della queue non serve più perché è creata in modo dinamico e casuale da RabbitMQ.
// Il codice rimane uguale al precedente fino all'istanza di ModelCentralized:
var ModelCentralized = Connection.CreateModel();
string QueueName = ModelCentralized.QueueDeclare("", false, true, true, null);
ModelCentralized.ExchangeDeclare(ExchangeName, ExchangeType.Fanout);
ModelCentralized.QueueBind(QueueName, ExchangeName, "");
QueueingBasicConsumer consumer = new QueueingBasicConsumer(ModelCentralized);
string consumerTag = ModelCentralized.BasicConsume(QueueName, false, consumer);
// Resto del codice per l'attesa dei messaggi e la sua visualizzazione uguale al precedenteAlla definizione della queue con la funzione QueueDeclare si č lasciato il nome vuoto perché sarŕ RabbitMQ ad assegnarcene uno con nome casuale. Non č importante il suo nome per la ricezione dei messaggi perché un altro processo, per inviarci i messaggi, utilizzerŕ il nome dell'exchange. ExchangeDeclare fa proprio questo: crea, se non esiste giŕ, un exchange e con il QueueBind č legata la queue con l'exchange. Inoltre viene definito questo exchance come Fanout: qualsiasi queue collegata a questo exchange, riceverŕ qualsiasi messaggio inviato. C'č una differenza in questo codice con il precedente: ora siamo noi che dobbiamo comunicare a RabbitMQ che abbiamo ricevuto ed elaborato il messaggio, e lo facciamo con questo codice:
string consumerTag = ModelCentralized.BasicConsume(QueueName, false, consumer);
Il secondo parametro, false, impostiamo il sistema perché siamo noi che vogliamo inviare il comandi di avvenuta ricezione che si completa con la riga successiva:
ModelCentralized.BasicAck(e.DeliveryTag, false);
L'invio dei messaggi non cambia molto se confrontato con il precedente, cambia solo il codice per l'invio:
ModelCentralized.BasicPublish(ExchangeName, "", basicProperties, msgRaw);
In questo caso viene specificato il nome dell'exchange e non il nome della queue. Avviati i due processi, la soluzione il risultato sarŕ uguale al precedente. Ma ora possiamo avviare due istanze del primo programma e vedremo che i messaggi saranno ricevuti da entrambi:
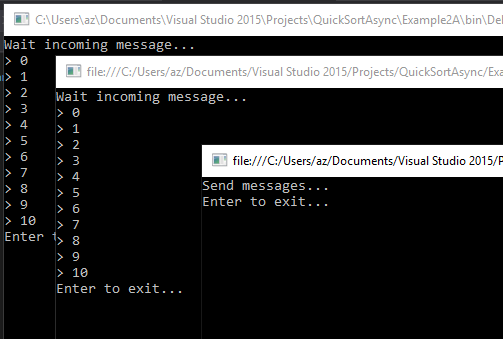
Potremo attivare tutte le istanze che vogliamo: tutte riceveranno i nostri messaggi.
Con l'uso dell'exchange possiamo definire oltre al Fanout visto in precedenza, anche la modalitŕ Topic: in cui possiamo specificare che il collegamento tra un exchange e una o piů queue venga attraverso a delle routing key con caratteri jolly. I caratteri jolly sono due: * e #. Ma non permettono la libertŕ che si potrebbe immaginare. Un errore che puň accadere ai novizi e pensare che l'uso dei caratteri jolly debba essere utilizzato nell'invio dei messaggi. Questo č sbagliato: questi devono essere utilizzati nella definizione dell'exchange. Il messaggio inviato dovrŕ avere sempre una routing key valida (o vuota). Innanzitutto le routing key devono essere definiti come parole separate dal punto. Esempio:
altezza.coloreocchi.genere
Se definiziamo due routing key di collegamento tra un exchange e due queue in questo modo:
basso.*.maschile *.marroni.*
E inviamo questi messaggi con queste routing key:
basso.azzurri.maschile alto.marroni.femminile alto.azzurri.femminile basso.marroni.maschile azzurri.maschile
Il primo sarŕ inviato solo alla prima queue, il secondo solo alla seconda queue, la terza a nessuna di esse, la quarta ad entrambi. L'ultima, non essendo composta da tre parole, sarŕ scartata.
Oltre all'asterisco possiamo usare il carattere hash (#):
#.maschile
La differenza č che con l'asterisco il filtro utilizzerŕ una sola parola mentre l'hash č un jolly completo e include qualsiasi parola o numero di parole al suo posto. La regola qui sopra accetterebbe:
basso.azzurri.maschile marroni.maschile magro.alto.marroni.maschile
L'esempio "Example3A" avvia due thread con due routing key differenti. Il codice č uguale agli esempi precedenti tranne che per queste due righe:
ModelCentralized.ExchangeDeclare(_exchangeName, ExchangeType.Topic); ModelCentralized.QueueBind(QueueName, _exchangeName, _routingKey);
Nella prima specifichiamo che il tipo di exchange č Topic, nel secondo, oltre al nome della queue e al nome dell'exchange, inseriamo anche le seguenti routing key:
*.red small.*
Nell'invio il codice č uguale agli esempi precedenti tranne per questa riga:
ModelCentralized.BasicPublish(ExchangeName, "small.red", basicProperties, msgRaw); ModelCentralized.BasicPublish(ExchangeName, "big.red", basicProperties, msgRaw); ...
Ecco la schermata di ouput:
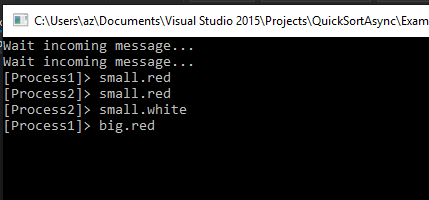
Se finora si č spinta l'attenzione all'invio dei messaggi con quasi tutte le sue sfaccettature - manca l'exchange con in modalitŕ direct che vedremo nell'esempio successivo e la modalitŕ header che non tratterň - e ora di muoverci nella direzione opposta e prestare maggiore attenzione alla modalitŕ di lettura dei messaggi dalla queue. Con i fonout message e i topic abbiamo visto che possiamo inviare i messaggi a piů queue alla volta alla quale č collegato un solo processo... e se collegassimo piů processi a un'unica queue? Ecco, siamo al punto piů interessante dell'utilizzo dei message broker. La queue quando riceverŕ i messaggi li distribuirŕ tra tutti i processi collegati:
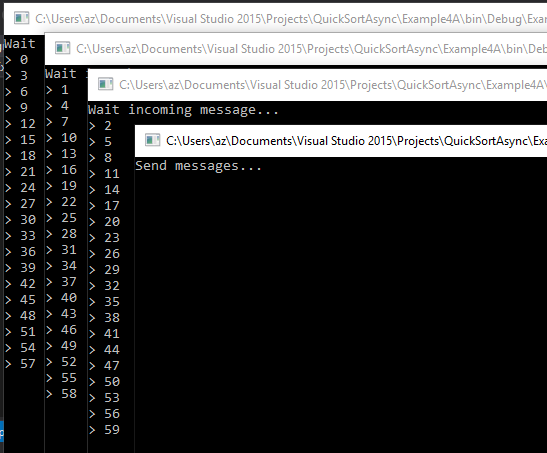
Possiamo vedere qui la distribuzione equa di tutti i messaggi tra tutti i processi. L'invio dei messaggi non č nulla di nuovo da quello che si visto finora: si usa il nome dell'exchange (in modalitŕ direct) e una routing key (non obbligatoria); avendo il messaggio in MsgRaw l'invio č semplice:
ModelCentralized.BasicPublish(ExchangeName, RoutingKey, basicProperties, msgRaw);
Un po' di novitŕ sono presenti nell'esempio per la lettura della queue (nel progetto da scaricare č Example 4A). Definiti i nomi della queue, dell'exchange e della routing key:
const string ExchangeName = "ExchangeExample4"; const string RoutingKey = "RoutingExample4"; const string QueueName = "QueueExample4";
... e connessi al solito modo:
var ModelCentralized = Connection.CreateModel(); ModelCentralized.QueueDeclare(QueueName, false, false, true, null); ModelCentralized.ExchangeDeclare(ExchangeName, ExchangeType.Direct); ModelCentralized.QueueBind(QueueName, ExchangeName, RoutingKey); ModelCentralized.BasicQos(0, 1, false);
Nella dichiarazione della queue abbiamo ora specificato il nome, non durable, non exclusive ma con l'autodelete. L'exchange č dichiarata come Direct. La novitŕ e la funzione richiamata "BasicQos". Qui specifichiamo che processo leggerŕ uno e solo un messaggio alla volta. La lettura dei messaggi avviene allo stesso modo:
var e = (RabbitMQ.Client.Events.BasicDeliverEventArgs)consumer.Queue.Dequeue();
Dopotutto questo sciolinare le possibilitŕ di RabbitMq e avere visto l'invio e la ricezione dei messaggi, č ora di tornare con i piedi per terra con esempi reali. Un processo che invia un messaggio e un altro, completamente indipendete che lo preleva dalla coda e lo visualizza va bene solo nella dimostrazioni e nella demo: tutt'al piů puň essere utili nell'invio di messaggi per il log e poco altro. Nel mondo reale un processo ne chiama un altro per richiedere dei dati. Il Request/reply pattern fa al caso nostro. Per ricrearlo con RabbitMQ, negli esempi visti finora, dobbiamo innanzitutto creare una queue pubblica dove inviare le richieste. E ora il problema: come puň il processo rispondere al processo richiedente i dati? La soluzione č semplice: il processo che richiede i dati deve avere una propria queue dove saranno depositate le risposte. Finora non siamo andati nel dettaglio dei messaggi ricevuti e avviati da RabbitMq. Possiamo specificare diverse proprietŕ utili per poi elaborare la comunicazione. Ecco il codice visto fino per l'invio con alcune proprietŕ aggiuntive:
IBasicProperties basicProperties = ModelCentralized.CreateBasicProperties(); basicProperties.MessageId = ... basicProperties.ReplyTo = ...; msgRaw = Encoding.Default.GetBytes(...); ModelCentralized.BasicPublish(ExchangeName, "", basicProperties, msgRaw);
MessageId e ReplyTo sono due proprietŕ stringa liberamente utilizzabili. E' facilmente intuibile che potranno essere utilizzati per specificare, nel caso di ReplyTo, la queue del processo richiedente. E MessageId? Lo possiamo utilizzare per specificare a quale richiesta stiamo rispondendo. Nell'esempio "Example5A" e "Example5B" facciamo tutto quanto detto finora. "Example5A" č il processo che elaborerŕ i nostri dati, in questo caso una banale addizione matematica. La parte piů importante č quella che attende la richiesta e invia la risposta:
var e = (RabbitMQ.Client.Events.BasicDeliverEventArgs)consumer.Queue.Dequeue();
IBasicProperties props = e.BasicProperties;
string replyQueue = props.ReplyTo;
string messageId = props.MessageId;
string content = Encoding.Default.GetString(e.Body);
Console.WriteLine("> {0}", content);
int result = GetSum(content);
Console.WriteLine("< {0}", result);
var msgRaw = Encoding.Default.GetBytes(result.ToString());
IBasicProperties basicProperties = ModelCentralized.CreateBasicProperties();
basicProperties.MessageId = messageId;
ModelCentralized.BasicPublish("", replyQueue, basicProperties, msgRaw);
ModelCentralized.BasicAck(e.DeliveryTag, false);In questo codice prendiamo il nome della queue del richiedente e il messageId che identifica la chiamata. Utilizzando un nuovo oggetto IBasicProperties (avremo potuto usare lo stesso ma in questo modo si capisce meglio l'utilizzo), impostiamo la proprietŕ del MessageId e inviamo la riposta al nome della queue prelevata alla richiesta.
Fin qui niente di complicatissimo. La parte piů intricata č quella del processo che richiamerŕ questo servizio perché dovrŕ nello stesso momento crearsi una queue privata ed esclusiva, e inviare le richieste alla queue pubblica. Non potendo usare una chiamata sincrona (e sarebbe assurdo), utilizzerň due thread, uno che invierŕ le richieste e un secondo per le risposte. Per gestire le richieste utilizzeremo un dictionary dove sarŕ salvato il messageId e la richiesta:
messageBuffers = new Dictionary<string, string>();
messageBuffers.Add("a1", "2+2");
messageBuffers.Add("a2", "3+3");
messageBuffers.Add("a3", "4+4");Quindi č definito il nome fittizio della queue privata dove il servizio dovrŕ inviare le risposte:
QueueName = Guid.NewGuid().ToString();
L'invio delle richieste č il seguente (come giŕ visto):
foreach (KeyValuePair<string, string> item in messageBuffers)
{
IBasicProperties basicProperties = ModelCentralized.CreateBasicProperties();
basicProperties.MessageId = item.Key; // a1, a2, a3
basicProperties.ReplyTo = QueueName;
msgRaw = Encoding.Default.GetBytes(item.Value); // 2+2, 3+3, 4+4
ModelCentralized.BasicPublish(ExchangeName, "", basicProperties, msgRaw);
}E ora il thread per le risposte:
while (true)
{
var e = (RabbitMQ.Client.Events.BasicDeliverEventArgs)consumer.Queue.Dequeue();
string content = Encoding.Default.GetString(e.Body);
string messageId = e.BasicProperties.MessageId;
Console.WriteLine("{0} = {1}", messageBuffers[messageId] , content);
ModelCentralized.BasicAck(e.DeliveryTag, false);
}Molto semplice, letta la risposta inviata da RabbitMq, si legge il MessageId con il quale si prende il testo della richiesta per potergli assegnare la corretta risposta (in questo caso č solo per la visualizzazione).
Anche in questo caso possiamo avviare piů processi in attesa di essere chiamato. Esso puň essere sulla stessa macchina, oppure potrebbe essere dall'altra parte del pianeta: unica regola perché possa rispondere a una richiesta č che sia raggiungibile e collegato a RabbitMQ. A questo punto č facile intuire la potenzialitŕ che avrebbe questa possibile strada: un message broker al centro e una o piů macchine collegate a esso su cui girano decine di micro servizi ognuno responsabile di una o piů funzioni. Nulla ci vieta di mettere, insieme alla funzione della somma qui sopra esposta, un servizio per la richiesta dell'elenco di articoli per un sito di e-commerce. Possiamo creare un altro micro service per la gestione degli utenti e del loro carrello. E il bello č che possiamo installarli sulla stessa macchina come in una webfarm con decine di server. Inoltre, al crescere delle necessitŕ, potremo installare lo stesso micro service su piů server - si ricordano le ascisse del cubo?
Siamo onesti: questa tecnica ha potenzialitŕ incredibili ma ha il classico fascino da demo dinanzi a clienti: bello finché rimane semplice. Alzando anche di poco l'asticella si scoprirŕ che solo passare da una queue a piů queue in una nostra applicazione rende il tutto dannatamente confuso e poco gestibile. Se si osserva solo il codice di Example5A si puň notare che, per rendere il codice piů breve possibile, ho lasciato il tutto in un unico thread e non in versione ottimale e ciň non aiuta completamente la comprensione dello stesso; inoltre per la gestione piů performante l'uso di thread separati per le richieste e le risposte sarebbe consigliabile, cosě come per la gestione di possibili multi queue. Il consiglio č incapsulare tutte queste funzioni cosě come ho provato nell'esempio finale che si puň trovare nella soluzione con il nome "QuickSortRabbitMQ". Quicksort? Dove avevamo giŕ parlato di esso? Ma certo, all'inizio di questo post. Da esso era nato tutto questo discorso che ci ha fatto spaziare dalla distribuzione di processi sino all’uso di un message broker. Anche se solo per scopo didattico, si immagini che creare un micro service per l'ordinamento di un array di interi. Come visto, il quicksort divide l'array in due sotto array grazie ad un valore pivot. E se questi due sotto array li ripassassimo allo stesso micro service e cosě via per avere l'array ordinato? Il micro service in questione rimarrŕ in attesa, grazie a rabbitMQ, di una richiesta diretta a lui o, per meglio dire, alla queue dove lui preleverŕ l'array da ordinare. Quindi avrŕ una seconda queue privata, dove aspetterŕ l'ordinamento degli array che lui stesso invierŕ alla queue principale. Incasinato, vero? Sě, questo č il modo di richiamare micro service con un message broker in modo ricorsivo, e la ricorsivitŕ č quella che abbiamo bisogno per il quicksort.
Spiegando con un esempio, avendo questo array da ordinare, lo inviamo alla queue principale del nostro micro service di ordinamento:
[4,8,2,6] -> Public queue
Al primo giro, il nostro micro service potrebbe dividere l'array in due sotto array con pivot 5, che saranno inviati a loro volto alla public queue:
[4, 2] -> Public queue [8, 6] -> Public queue
Ora due volte sarŕ richiamato lo stesso micro service che ordinerŕ i due soli numeri presenti e dovrŕ restituirli... sě, ma a chi? Semplice, a se stesso... E come? Potremo usare ancora la public queue, ma questo comporta un problema non di poco conto. Se si ricorda l'algoritmo di ordinamento quicksort, lo stesso metodo attende i due array inviati ma questa volta ordinati, quindi deve restituire l'unione dei due array a chi lo aveva chiamato. Quindi dobbiamo tenere traccia dei due array inviati per essere uniti: e come si potrebbe fare se questo micro service avesse piů istanze attive e un'array finisse in un processo sulla macchina A e il secondo array in un processo sulla macchina B? Il processo che invia la richiesta DEVE ESSERE quello che riceve le risposte viste ora, e lo possiamo fare solo creando una queue privata nello stesso processo e con l'uso delle property nei messaggi, indirizzare la risposta alla queue corretta.
[2,4] -> Private queue processo chiamante [6,8] -> Private queue processo chiamante
Il processo chiamante rimarrŕ in attesa anche sulla queue private di entrambe le risposte che unirŕ prima di restituirla a sua volta al processo chiamante, che potrebbe essere ancora se stesso o un altro.
Giŕ si puň immaginare la complessitŕ di scrivere del codice che, utilizzando su piů thread, gestisca questo casino. Per semplificare le cose ho creato una piccola libreria che, in completa autonomia, crea i thread di cui ha bisogno e grazie agli eventi comunica con il processo i messaggi provenienti dal message broker. Nel codice della soluzione di esempio č nel progetto "RabbitMQHelperClass". Questa libreria č utilizzata dal progetto "QuickSortRabbitMQ". Siamo arrivati a destinazione: qui troviamo la console application che utilizza questo message broker per la comunicazione delle "porzioni" di array da ordinare con il quicksort. La prima parte č semplice: creato un array di 100 elementi e popolato con numero interi casuali da 1 a 100, ecco che viene istanziata la classe che ci faciliterŕ il lavoro (o almeno ci prova).
using (rh = new RabbitHelper("localhost"))
{
rh.AddPublicQueue(queueName, exchangeName, routingKey, false);
var privateQueueThread = rh.AddPrivateQueue();// "QueueRicorsiva");
privateQueueName = privateQueueThread.QueueInternalName;E' presente la funzione per la creazione di una queue public (dove saranno inviate le richieste di array da ordinare). Quindi č creata una queue privata, che sarŕ usata per restituire al chiamante l'array ordinato.
var privateQueueResultThread = rh.AddPrivateQueue();// "QueueFinale");
privateQueueNameResult = privateQueueResultThread.QueueInternalName;Qui č creata una ulteriore queue privata: questa sarŕ utilizzata perché sarŕ quella che conterrŕ il risultato finale alla fine del ciclo ricorsivo (a differenza delle queue pubblica che č univoca, la queue privata possono essere piů di una). E' ora di collegare gli eventi:
string messageId = RabbitHelper.GetRandomMessageId();
rh.OnReceivedPublicMessage += Rh_OnReceivedPublicMessage;
privateQueueThread.OnReceivedPrivateMessage += Rh_OnReceivedPrivateMessage;
privateQueueResultThread.OnReceivedPrivateMessage += Rh_OnReceivedPrivateMessageResult;In messageId č un guid univoca casuale. OnReceivePublicQueue č l'evento che sarŕ eseguito quando arriverŕ un messaggio alla queue pubblica prima creata. La stessa cosa per le due queue private con: OnReceivedPrivateMessage. E' ora di far partire la nostra procedura di ordinamento:
var msgRaw = RabbitHelper.ObjectToByteArray<List<int>>(arrayToSort); rh.SendMessageToPublicQueue(msgRaw, messageId, privateQueueNameResult);
Come visto in precedenza, tutto quello che č trasmesso via RabbitMQ viene serializzato in formato di array di byte. La funzione ObjectToByteArray fa questa operazione (ne riparleremo anche piů avanti) e SendMessageToPublicQueue invia l'array da ordinare alla queue pubblica; inoltre viene inviato anche il nome della queue privata che rimarrŕ in attesa della risposta finale dell'ordinamento completato. Ok, ora la classe che avrŕ creato per noi thread per l'elaborazione delle queue, riceverŕ il messaggio e invierŕ il suo contenuto, con altre informazioni, all'evento prima definito "OnReceivedPublicMessage". Qui č stata riscritta la funzione di ordinamento vista all'inizio di questo post:
private static void Rh_OnReceivedPublicMessage(object sender, RabbitMQEventArgs e)
{
string messageId = e.MessageId;
string queueFrom = e.QueueName;
var toOrder = RabbitHelper.ByteArrayToObject<List<int>>(e.MessageContent);
Console.Write(" " + toOrder.Count.ToString());
if (toOrder.Count <= 1)
{
var msgRaw = RabbitHelper.ObjectToByteArray<List<int>>(toOrder);
rh.SendMessageToPrivateQueue(msgRaw, messageId, queueFrom);
return;
}Preso il contenuto dell'array, piů le informazioni (l'id univoco del messaggio e la coda a cui dovremo rispondere), si controlla che la sua dimensione sia maggiore di uno, altrimenti manda come risposta, alla queue privata, lo stesso array inviato. Il resto del codice divide dal valore pivot gli elementi dell'array minore e maggiore e invia questi due array alla queue pubblica:
var rs = new RequestSubmited
{
MessageParentId = messageId,
MessageId = RabbitHelper.GetRandomMessageId(),
QueueFrom = queueFrom,
PivotValue = pivot_value
};
lock (requestCache)
{
requestCache.Add(rs);
}
var msgRaw1 = RabbitHelper.ObjectToByteArray<List<int>>(less);
rh.SendMessageToPublicQueue(msgRaw1, rs.MessageId, privateQueueName);
var msgRaw2 = RabbitHelper.ObjectToByteArray<List<int>>(greater);
rh.SendMessageToPublicQueue(msgRaw2, rs.MessageId, privateQueueName);RequestSubmited č una classe che contiene solo delle proprietŕ per l'identificazione della risposta inviata da un altro (o dallo stesso) processo proveniente dal message broker.
Solo quando gli array sono ridotti a una unitŕ viene inviato il tutto alle queue private: Rh_OnReceivedPrivateMessage. Questo evento dev'essere richiamato due volte per le due parti di array divise dal valore pivot. La prima parte di questa funzione non fa altro che aspettare che entrambe arrivino alla funzione prima di essere unite. L'oggetto di tipo RequestSubmited č usato per richiamare i valori dell'id del messaggio e del pivot:
private static void Rh_OnReceivedPrivateMessage(object sender, RabbitMQEventArgs e)
{
string messageId = e.MessageId;
string queueFrom = e.QueueName;
... codice per riprendere entrambe le queue
... infine viene mandato l'array ordinato alla queue privata
var msgRaw = RabbitHelper.ObjectToByteArray<List<int>>(result);
rh.SendMessageToPrivateQueue(msgRaw, messageParentId, queueParent);
}Non mi soffermo sul codice che esegue l'ordinamento (che abbiamo giŕ visto) e per recuperare le due code (č un banale controllo su un oggetto List<...>); inoltre il codice sorgente č facilmente consultabile ed č possibile testarlo. Vediamo perň l'effetto finale:
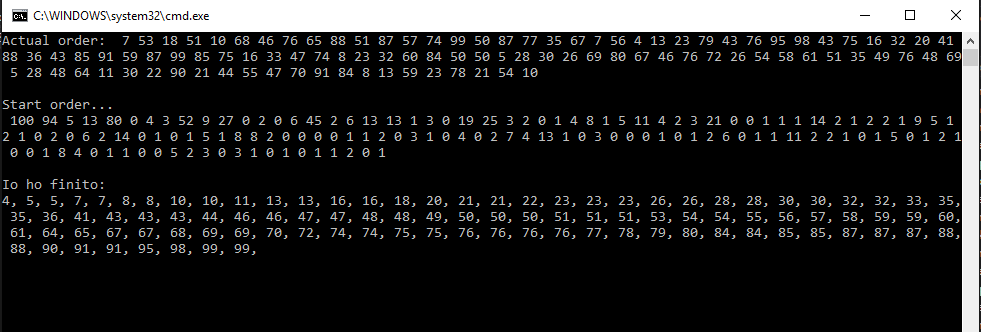
Il bello č possiamo attivare piů volte questo processo per permettere l'ordinamento in parallelo su piů processi, anche su diverse macchine:
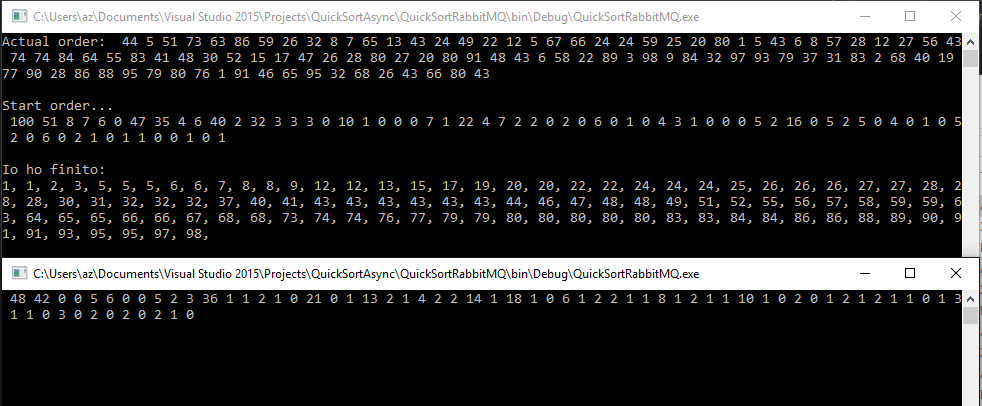
Nella window sottostante č visibile solo un'informazione di debug che sono il numero di elementi inviati.
Se ci fosse un premio su come complicare una procedura per sua natura semplice, dopo quest'ultimo codice potrei concorrere per il primo premio senza problemi. In effetti, questo esempio - il quicksort - presenta un grave problema perché possa essere utilizzato con profitto per il calcolo distribuito: il primo tra tutti č che le porzioni di array da ordinare sono da inviare completamente quando, con molto meno e con solo i reference all'array da ordinare, il tutto si sistemerebbe in modo molto piů veloce. Ma questo mi era venuto in mente come esempio...
Iniziamo a tirare qualche conclusione: la piů semplice č che devo lavorare meglio sugli esempi da portare; la seconda conclusione č che effettivamente il message broker (in questo caso RabbitMQ) esegue molto bene il suo lavoro se decidiamo di abbracciare il mondo dei micro service. Ritornando al cubo, possiamo far comunicare i processi su qualsiasi ascissa in modo veloce e affidabile. Inoltre possiamo fare in modo che anche comunicazione tra processi siamo facilitati anche per l'invio di cambiamenti di configurazione. Tornando a un esempio precedente dove abbiamo utilizzato la comunicazione fanout (senza filtri, a tutte le queue collegate a quell'exchange). E ora pensiamo a una moltitudine di microservice avviati su uno o piů server. Di default questi potrebbero avere un proprio file di configurazione utilizzato all'avvio dello stesso: ma cosa succederebbe se dobbiamo cambiare uno di questi parametri? Di default su tutti i processi potrebbe essere inserito il nome di un server ftp dove inserire dei file. In caso si dovesse cambiare l'URI di questo server, che cosa dovremo fare? Modificare tutti i file di configurazione di tutti i processi? E se ce ne dimentichiamo qualcuno? Soluzione piů pratica potrebbe essere la predisposizione di un micro service che fa solo questo: tutti i processi, una volta avviati, leggerebbero di default il file di configurazione salvato insieme all'eseguibile, e di seguito potrebbe richiedere a quel microservice la nuova configurazione (che potrebbe sovrascrivere quelle precedente). Oppure ogni microservice potrebbe avere una queue privata collegata a un exchange che potrebbe inviare modifiche alla configurazione in tempo reale. Questo passaggio ci consentirebbe addirittura di inviare il nuovo URI per il server FTP, aspettare che tutti i processi si siano aggiornati, quindi spegnere il primo server tranquilli che nessuno lo sta utilizzando.
Ripetendoci, possiamo fare in modo di scrivere una miriade di microservice per le operazioni piů disparate: dall'accesso ad una tabella di un database, all'invio di email, alla creazione di grafici; ogni servizio raggiungibile grazie ad un exchange e, a seconda delle esigenze che potrebbe aumentare, poter collegare piů processi che il message broker possa richiamare bilanciando il carico tra tutte le risorse disponibili. E l'interoperabilitŕ? Il message broker non si crea problemi su chi o cosa lo chiami. Potrebbe essere cosě come un client scritto con il Framework .Net come fatto in questo post, oppure Java... In questo caso, come comunichiamo con oggetti piů complessi delle stringhe usate nei primi esempi e inviamo, come nell'esempio del quicksort, oggetti serializzati nativi per una determinata tecnologia?
Vediamo che succede. Nell'Esempio6A proviamo proprio questo: innanzitutto creiamo un oggetto semplice da serializzare come una lista di interi:
var content = new int[] { 1, 2, 3, 4 };Quindi la inviamo a RabbitMQ con il codice che conosciamo:
IBasicProperties basicProperties = ModelCentralized.CreateBasicProperties();
var msgRaw = ObjectToByteArray<int[]>(content);
ModelCentralized.BasicPublish("", QueueName, basicProperties, msgRaw);ObjectToByteArray č una funzione usata anche dall'esempio del quicksort:
public static byte[] ObjectToByteArray<T>(T obj) where T : class
{
BinaryFormatter bf = new BinaryFormatter();
using (var ms = new MemoryStream())
{
bf.Serialize(ms, obj);
return ms.ToArray();
}
}E ora non ci rimane che vedere che cosa succede, una volta inserito questo oggetto in una queue, come leggerlo con un'altra tecnologia. Proviamo con node.js (confesso che questo mio interesse per i message broker sia nato per questa tecnologia e solo dopo l'ho "convertita" al mondo del Framework .Net). Avendo installato sulla propria macchina npm e nodejs, da terminale, basta preparare i pacchetti:
npm install amqp
Quindi un text editor:
var amqp = require('amqp');
var connection = amqp.createConnection({ host: 'localhost' });
// Wait for connection to become established.
connection.on('ready', function () {
// Use the default 'amq.topic' exchange
connection.queue('Example6', function (q) {
// Catch all messages
q.bind('#');
// Receive messages
q.subscribe(function (message) {
// Print messages to stdout
console.log(message.data.toString());
});
});
});NodeJs rende il tutto piů banale grazie alla sua natura asincrona. Connesso al server di RabbitMQ su localhost, all'evento ready al momento della connessione ci si connette alla queue "Example6" (la stessa queue usata nell'Esempio6A) e con il subscribe si attende la risposta. Lanciamo questa mini app:
node example1.js
Quindi avviamo Esempio6A.exe:
Ovviamente, NodeJs non sa che farsene di quell'array di byte incomprensibili. E la soluzione? Io non so qual č la strada piů performante e migliore, ma la piů semplice e riutilizzabile per qualsiasi tecnologia č grazie a json. Il codice di invio prima visto lo possiamo trasformare in questo modo:
var json = new JavaScriptSerializer().Serialize(content);
msgRaw = Encoding.Default.GetBytes(json);
ModelCentralized.BasicPublish("", QueueName, basicProperties, msgRaw);E inserito nella queue, una volta letto dall'app in nodejs avremo:
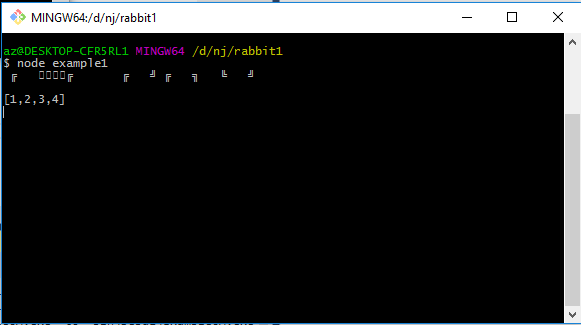
Perfetto, con nodejs l'uso di json č semplicissimo cosě come con il Framework .Net visto che come possiamo serializzare un oggetto in formato json lo possiamo anche trasformarlo nel suo formato originale. Ci sono soluzioni migliori? Sono disponibile a qualsiasi consiglio, come sempre.
E' ora di chiudere. Conclusioni? Non ce ne sono. Un message broker semplifica la struttura di app basate su microservice. E' l'unica scelta? No. Avrei voluto continuare questo discorso con la comunicazione tra microservice grazie a Redis dell'Italiano Salvatore Sanfilippo, ma la mia conoscenza in merito č ancora deficitaria e mi sono scontrato subito con delle problematiche che non ho ancora risolto (il tempo disponibile č quello che č). Uno dei vantaggi che ho notato immediatamente a confronto di RabbitMQ č la velocitŕ spaventosamente superiore. Forse in futuro affronterň l'argomento su questo blog... sempre se, lo ripeto, la voglia e il tempo me lo permetteranno. Altra soluzione č con l'utilizzo di Akka.Net: anche in questo caso le prestazioni sono superiori e il tutto č piů semplificato per la comunicazione di messaggi; il problema grosso in cui mi sono imbattuto subito č la difficile interoperabilitŕ tra diverse tecnologie, ma la mia conoscenza da novizio non mi hanno fatto andare oltre le basi. Ok, basta cosě.
Tutto il codice di esempio č disponibile qui:
https://bitbucket.org/sbraer/quicksort-with-rabbitmq/overview

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
- C# e Net 6 in Kubernetes con Prometheus e Grafana, il 12 gennaio 2022 alle 21:58
- Snaturare Kubernetes evitando i custom container Docker, il 6 gennaio 2022 alle 19:40
- Provando Kaniko in Kubernetes come alternativa a Docker per la creazione di immagini, il 18 dicembre 2021 alle 20:11
- Divertissement con l'OpenID e Access Token, il 6 dicembre 2021 alle 20:05
- Operator per Kubernetes in C# e Net Core 6., il 28 novembre 2021 alle 19:44
- RBAC in Kubernetes verso gli operator, il 21 novembre 2021 alle 20:52