
SP vs Linq vs Entity Framework in scrittura
La sola sicurezza che avevo era di quanto Linq e l'Entity Framework fossero piů lenti. Mi preparo un banale test per l'inserimento di un buon numero di record in un database Sql server 2005 per un benchmark personale. Creo due tabelle collegate dalla struttura molto semplice:
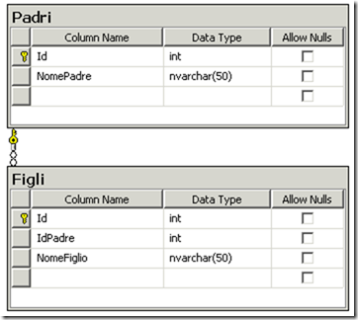
Il mio test č molto banale: creare un array casuale di 100 padri, e ogni padre un array casuale di 100 figli. Gli sfidanti e le armi utilizzate sono i seguenti:
- Collection tradizionale e stored procedure (una per ogni tabella) richiamata con il Prepare del Command per il massimo delle prestazioni.
- Collection inserita direttamente in un DataContext creato da Visual Studio 2008.
- Collection inserita direttamente nelle collection create dall'Entity Framework.
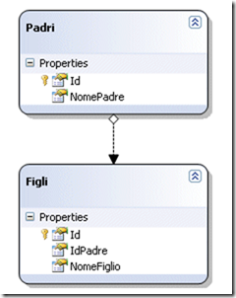
Ecco di seguito il DataContext usato da Linq:
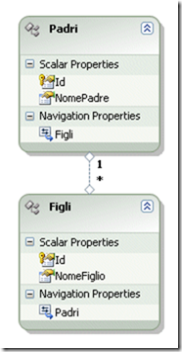
E l'Entity Framework creato sempre da VS2008:
Avvio piů volte i test per ogni tecnologia utilizzata. La media č la seguente:
| Stored procedure | Linq to Sql | Entity Framework |
| 6.75s | 20.60s | 12.93s |
Sulla maggiori performance dell'inserimento diretto da codice con le stored procedure, come giŕ detto, non ne avevo il minimo dubbio: il tutto č ottimizzato al meglio, ed ho cercato anche da codice di ottimizzare il piů possibile la creazione di oggetti e il passaggio di parametri. La delusione č stata invece per Linq, che le prende sonoramente anche dall'Entity Framework che si dimostra molto piů efficiente del tradizionale Linq to Sql.
Leggendo con il Profiler le query inviate da Linq to Sql e dall'Entity Framework, si notano alcune differenze nelle query di inserimento create:
-- Linq to Sql
-- Inserimento nella tavella 'Padri'
exec sp_executesql N'INSERT INTO [dbo].[Padri]([NomePadre])
VALUES (@p0)
SELECT CONVERT(Int,SCOPE_IDENTITY()) AS [value]',N'@p0 nvarchar(7)',@p0=N'Padre 1'
--
-- Inserimento nella tabella 'Figli'
exec sp_executesql N'INSERT INTO [dbo].[Figli]([IdPadre], [NomeFiglio])
VALUES (@p0, @p1)
SELECT CONVERT(Int,SCOPE_IDENTITY()) AS [value]',N'@p0 int,@p1 nvarchar(9)',@p0=400,@p1=N'Padre 1 1'
---- Entity Framework
-- Inserimenti nella tabella 'Padri'
exec sp_executesql N'insert [dbo].[Padri]([NomePadre])
values (@0)
select [Id]
from [dbo].[Padri]
where @@ROWCOUNT > 0 and [Id] = scope_identity()',N'@0 nvarchar(7)',@0=N'Padre 1'
--
-- Inserimento nella tabella 'Figli'
exec sp_executesql N'insert [dbo].[Figli]([IdPadre], [NomeFiglio])
values (@0, @1)
select [Id]
from [dbo].[Figli]
where @@ROWCOUNT > 0 and [Id] = scope_identity()',N'@0 int,@1 nvarchar(9)',@0=1600,@1=N'Padre 1 1'
La cosa che salta all'occhio subito č il differente modo di prendere l'id del record appena inserito e sembra, e lo ripeto, sembra, che sia piů performante quello utilizzato dall'Entity Framework anche se, la differenze in peggio tra le due tecnolgie, potrebbero essere invece a livello di codice del Framework nelle sue creazioni delle query.
Ora č tardi per investigare oltre. Ho fatto appena un viaggio di circa tre ore di pullman e sono stanco... Ma prima, si possono tirare conclusioni? Il mio test puň essere un caso reale di codice? La stanchezza mi sta spegnendo la ragione... mi fermo qui

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
- C# e Net 6 in Kubernetes con Prometheus e Grafana, il 12 gennaio 2022 alle 21:58
- Snaturare Kubernetes evitando i custom container Docker, il 6 gennaio 2022 alle 19:40
- Provando Kaniko in Kubernetes come alternativa a Docker per la creazione di immagini, il 18 dicembre 2021 alle 20:11
- Divertissement con l'OpenID e Access Token, il 6 dicembre 2021 alle 20:05
- Operator per Kubernetes in C# e Net Core 6., il 28 novembre 2021 alle 19:44
- RBAC in Kubernetes verso gli operator, il 21 novembre 2021 alle 20:52