
Storage persistente con Kubernetes e AWS
Qui avevo scritto alcune mie esperienze con Kubernetes. In quel post avevo affrontato alcune problematiche per l'avvio di una architettura semplice composta da tre istanze di MongoDb in ReplicaSet e di una web application che permetteva il loro accesso. Il tutto era stato presentato in un ambiente locale grazie a Minikube. E' arrivato il momento di fare le cose sul serio cercando di pubblicare il tutto su uno dei vari cloud per rendere il tutto usufruibile pubblicamente su Internet.
La mia scelta cade su AWS - il semplice motivo č perché ci lavoro spesso con questo cloud. AWS mette a disposizione un ambiente completo per la costruzione di una infrastruttura basata su Kubernetes in pochi passaggi e con una interfaccia web completa: Amazon Elastic Kubernetes Service (EKS). La prima premessa da fare, se si vuole utilizzare per imparare a padroneggiare Kubernetes, č meglio cominciare con Docker Desktop, Minikube o costruendosi in casa una piccola rete con qualche macchina virtuale seguendo le guide piů o meno ufficiali per la configurazione. Questo aiuterŕ a comprendere meglio il funzionamento di tutto il sistema, e solo quando si vorrŕ creare qualcosa di piů complesso si potrŕ passare a EKS (o altri cloud) che facilitano enormemente la creazione di tutto, dai nodi master che reggeranno il tutto, ai worker node dove gireranno i nostri pod.

Dopo questa rapida premessa ecco l'obbiettivo di questo post - per complicare un po' le cose abbandonerŕ l'esempio precedente, che avevo utilizzato anche per scoprire le differenze tra Docker Swarm e Kubernetes - e creerň una web application in ASP.NET Core 3.1 che avrŕ come base dati un cluster composto da tre istanze di Mysql in replica. All'interno della web application anche la gestione dell'Identity ho creato delle mie classi custom che useranno proprio quel database per salvare le informazioni - ho preferito non usare librerie apposite come Pomelo.EntityFrameworkCore.MySql o la versione ufficialmente supportata perché ho riscontrato stranezze sulle versioni delle librerie incluse. L'identity gestirŕ per me l'autenticazione e permetterŕ l'accesso a determinate pagine con il controllo della role degli utenti. Infatti ho inserito una semplice pagina dove sono visualizzati degli articoli a 'mo di wikipedia che utilizza tre livelli di autenticazione:
- Accesso anonimo: č solo possibile visualizzare la lista degli articoli presenti.
- Accesso con role users: č possibile vedere anche il contenuto dell'articolo.
- Accesso con role admin: č possibile modificare il contenuto dell'articolo e crearne di nuovi.
Nulla di complicato, il codice del progetto č possibile trovarlo qui. Dovendo utilizzare questa webapplication all'interno di un container Docker ho fatto delle piccole aggiunte per permettere il passaggio di parametri grazie alle variabili di ambiente; nel mio caso ho aggiunto:
- MySqlServerName: ip o nome del server.
- MySqlDatabaseName: nome del database da utilizzare.
- MySqlUsername: username da utilizzare per l'autenticazione.
- MySqlPassword: password.
Utilizzando tre istanze in Replica di Mysql, dove un'istanza - č solo una! - č utilizzata per la scrittura e le altre due solo in lettura, sono presenti le stesse voci qui sopra ma per l'accesso in sola modalitŕ lettura: MySqlServerNameReader, MySqlDatabaseNameReader e cosě via. Inoltre queste informazioni sono inseribili anche come contenuto di file, nel caso tutte alle voci viste finora č sufficiente aggiungere "File" al nome stesso; per esempio, se l'username fosse inserito nel file "/etc/secret-information/username", per dare questa informazioni alla web application, potrň utilizzare la variabile d'ambiente MySqlUsernameFile il cui contenuto sarŕ il nome del file compreso di path.
E' arrivato ora il momento di creare i vari file per la creazione di tutte le risorse all'interno di Kurbenetes. Come nel post precedente inizio con la definizione dei secret, dove inserirň le credenziali che voglio utilizzare per MySql.
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
databaseName: "Test1"
rootPassword: "1234567"
username: "a1"
password: "b1"
mysqlReadinessFile.sh: |
mysql -uroot -p1234567 --protocol tcp -h 127.0.0.1 -e "SELECT 1"rootPassword č la password che userň come root del database MySql e l'utente a1 con relativa password che sarŕ utilizzata dalla web application per l'accesso al database. mysqlReadinessFile.sh merita una spiegazione: ho inserito qui questo banale script perché sarŕ utilizzato da Kurbenetes per il controllo dell'attivitŕ dell'istanza di MySql: dovendo questo codice utilizzare le credenziali ho preferito NON inserirlo come parametro in chiaro nella definizione dei pod del database e non ho potuto trovare un altro modo per poter passare queste credenziali alla funzione readiness di Kubernetes.
I file necessari per la creazione delle tre istanze di MySql in Kubernetes li ho presi dalla documentazione ufficiale a questo link. Io ho solo aggiunto le varie modifiche per l'utilizzo di credenziali e per un minimo di sicurezza del tutto. Incluso in questi file l'utilizzo del ConfigMap. Questo oggetto puň contenere configurazioni delle applicazioni come i file: ha la stessa funzionalitŕ dei secret ma senza l'assillo della sicurezza (e infatti qui non inserirň password o altro che potrebbero compromettere la sicurezza). Cosě come nell'esempio nella documentazione ufficiale:
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
# Apply this config only on the master.
[mysqld]
log-bin
slave.cnf: |
# Apply this config only on slaves.
[mysqld]
super-read-only
Sql1-StructureUsers.sql: |
CREATE TABLE IF NOT EXISTS `AspNetUsers` (
`Id` varchar(255) NOT NULL,
`UserName` varchar(256) DEFAULT NULL,
`NormalizedUserName` varchar(256) DEFAULT NULL,
`Email` varchar(256) DEFAULT NULL,
`NormalizedEmail` varchar(256) DEFAULT NULL,
`PasswordHash` longtext,
PRIMARY KEY (`Id`),
UNIQUE KEY `UserNameIndex` (`NormalizedUserName`),
KEY `EmailIndex` (`NormalizedEmail`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
...Vengono definiti vari file. Il primo - master.cnf - č per la singola istanza Master di MySql, il secondo per le istanze in sola lettura. Di mio ho aggiunto quattro file contenenti codice SQL per la creazione delle tabelle e dati da inserire (user e altro) che saranno eseguiti nel pod dove č presente il container di MySql. Ulteriori info rimando alla pagina del progetto iniziale inserito prima, anche perché preferisco soffermarmi su altro. Infatti, nel post precedente dedicato a Kubernetes, avevo solo sfiorato l'argomento della gestione dello storage dedicandogli una riga o poco piů, quando in precedenza avevo usato una miriade di parole per la gestione dei volume a cui attingevo per i secret e lo scambio di file tra i vari container del pod. Cosě come in Docker, i volume servono a collegare uno storage esterno al container in cui il software puň salvare dati che non devono essere persi - il classico esempio č la directory dove un qualsiasi database salva i dati, se quel container fosse riavviato per un qualsiasi motivo, questi dati sarebbero persi. E' nella natura effimera dei container di Docker e, di conseguenza, dei container all'interno dei pod di Kubernetes, non potere essere utilizzati per la memorizzazione dei dati che non si vuole perdere. In Docker la soluzione piů semplice č dichiarare una directory sull'Host dove gira Docker perché questa venga utilizzata dal software all'interno del container per salvare i dati: in questo modo possiamo riavviare il tutto quante volte vogliamo senza rischi di perdita di file. Con Kubernetes questa cosa č ancora presente ma non consigliata: il salvataggio dei dati in una directory dell'host preclude lo spostamento di un pod (e del container al suo interno) su altre macchine in caso di necessitŕ (riavvio dell'host per esempio). Minikube offre questo servizio ma girando su un'unica macchina, per sua natura, non crea alcun problema per eventuali test. Nei vari servizi di cloud dove si possono creare decine di macchine non č una saggia idea utilizzare lo storage diretto sull'host, ma per fortuna, nei cloud dove č automatizzata la creazione dell'infrastruttura di Kubernetes - Aws, Azure, Linode, ecc... - sono disponibili feature apposite per la creazione automatizzata di dischi da collegare ai container - come cercherň di mostrare tra poco per AWS. In un ambiente di produzione dove si ospita in casa tutta l'infrastruttura di macchine per Kubernetes, si possono usare altri strumenti come Glusterfs o simili.
Per la generazione del mio progetto - web application e istanze di MySql - ho creato sei file:
- mysql-secret.yaml: dove ho inserito le credenziali, come ho scritto sopra.
- mysql-configmap.yaml: come sopra, contiene la configurazione per i database.
- mysql-services.yaml: crea i service su cui verranno esposte le istanze di MySql in modo che possano essere chiamate dalla web application.
- mysql-statefulset.yaml: contiene la configurazione per la creazione dello StatefulSet per le tre istanze di MySql; all'interno sono presenti anche gli InitContainer per la configurazione e per il backup/restore automatico dei database.
- webapp.yaml: contiene il deployment della web application e il suo service.
- ingress.yaml: permette la pubblicazione del servizio della web application su internet.
Dei primi due ne ho giŕ parlato. Per la creazione dei service:
# Headless service for stable DNS entries of StatefulSet members.
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None # <- Headless
selector:
app: mysql
---
# Client service for connecting to any MySQL instance for reads.
# For writes, you must instead connect to the master: mysql-0.mysql.
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysqlIl primo servizio viene definito come Headless grazie all'attributo ClusterIp impostato su None, perché di questo lo si puň trovare spiegato nel mio post precedente e nella documentazione ufficiale. Il secondo servizio, invece, usato in una connessione, permette l'utilizzo casuale di uno dei server sottostanti, comodo per suddividere le richieste tra tutte le istanze di MySql attive.
Passando ora alla creazione di MySql in replica su tre istanze, nel file yaml in questione nella parte finale si trova:
volumeClaimTemplates:
- metadata:
name: data
spec:
#storageClassName: fast
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10GiQuesto informa Kubernetess che vogliamo usare come StorageClass il servizio di AWS di default (notare anche i parametri successivi dove si puň scegliere il tipo di storage e il tipo di file system e che il parametro storageClassName puň essere omesso). Se avessi voluto usare Linode al posto di AWS non dovevo cambiare nulla, perché anche Linode offre un suo StorageClass di default. Fin qui tutto č bello e semplice, ma cos'č uno storage class?
Si deve fare un passo indietro. Kubernetes permette la gestione dei volume e mette a disposizione numerosi tipi, molti creati esternamente. Nel mio post precedente avevo usato emptyDir che č per sua natura non dev'essere usato per la persistenza dei dati. Ma ecco una semplice lista dei volume gestibili presenti di default:
- emptyDir: č uno storage interno che vive e muove insieme al suo pod.
- secret: anche i secret sono un tipo di storage in grado di mappare i secret come file in una directory accessibile dai container nei pod.
- hostPath: condivide una directory dell'host con i container; questo permette il salvataggio sicuro dei dati nell'host dove viene istanziato il pod, ma preclude la possibilitŕ di spostarlo al di fuori di quell'host.
- gitRepo: monta uno storage con il contenuto di un repository di git.
- NFS: permette l'accesso dai pod al file system condiviso NFS.
Oltre a questi sono disponibili quelli delle societŕ di cloud, come l'awsElasticBlockStore (per AWS), l'azureDisk per Azure, gcePersistentDisk per Google e cosě via. In pratica possiamo creare un volume nel nostro cloud e utilizzarlo all'interno di Kubernetes dando la possibilitŕ altresě di salvaguardare i dati salvati. Ecco un esempio veloce. In AWS, nella sezione EBS (Elastic Block System) creo un disco da 1GB:

Mi segno il Volume ID: vol-03e506cbf3d033647. Ora creo un pod e monto una directory in modo che questo disco sia accessibile:
apiVersion: v1
kind: Pod
metadata:
name: test1
spec:
volumes:
- name: test-data
awsElasticBlockStore:
volumeID: vol-03e506cbf3d033647
fsType: ext4
containers:
- image: nginx
name: testnginx
volumeMounts:
- name: test-data
mountPath: /mnt/dataNella sezione volumes ho inserito il nome e il tipo di storage: awsElasticBlockStore con il tipo di file system e il volume id creato in AWS. Nella sezione volumeMounts monto il disco EBS alla directory /mnt/data. Ora in EKS di AWS (si vedrŕ poi come avviare il tutto in modo semplice), istanzio questo pod:
# kubectl apply -f other.yaml pod/test1 created # kubectl get po NAME READY STATUS RESTARTS AGE test1 1/1 Running 0 34s
Il container avvia NGINX, ma per la veritŕ non mi interessa nulla di lui, ora voglio accedere per poter controllare la directory che mi interessa:
# kubectl exec -it test1 -- /bin/bash root@test1:/# cd /mnt/data/ root@test1:/mnt/data# echo "Hello-world!" > msg.txt root@test1:/mnt/data# cat msg.txt Hello-world!
Ho creato il file msg.txt nel disco esterno, ora controllo che mantenga i dati anche in caso di riavvio del pod:
# kubectl delete -f other.yaml pod "test1" deleted # kubectl apply -f other.yaml pod/test1 created # kubectl exec -it test1 -- /bin/bash root@test1:/# cd /mnt/data/ root@test1:/mnt/data# cat msg.txt Hello-world!
Questo conferma che i dati sono al sicuro dal riavvio o eventi inattesi. Questa operazione si č svolta con due azioni: creazione preventiva di un disco, quindi, la sua assegnazione al pod. Sono normalmente azioni eseguite da due figure separate all'interno di un'azienda. Quindi si avrebbe l'ipotetica situazione di una persona che crea la struttura del pod e le sue risorse e richiede all'amministratore dei server (AWS o meno) per avere il volume id di un disco, questo per ogni nuovo pod creato. Per risolvere questo prima problema si č pensato di creare una strato supplementare tra il pod e lo storage vero e proprio, grazie al PersistentVolumeClaim. Questo permette, alla persona che crea la struttura del pod, di inserire la richiesta dello storage all'interno della sua definizione. Ecco un esempio come quello precedente a fatto all'interno di Minikube:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: my-pv-claim
spec:
storageClassName: ""
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Mi
---
kind: Pod
apiVersion: v1
metadata:
name: task-pv-pod
spec:
volumes:
- name: my-pv-storage
persistentVolumeClaim:
claimName: my-pv-claim
containers:
- name: task-pv-container
image: nginx
volumeMounts:
- mountPath: /mnt/data
name: my-pv-storageNella prima parte ho definito il nuovo tipo di oggetto PersistentVolumeClaim. In esso specifico le mie esigenze per lo storage - in questo caso voglio un disco che possa essere letto e scritto solo da un pod (ReaderWriteOnce) con la dimensione di un megabyte. Nella definizione del pod, invece, nella sezione volumes, specifico che il disco da agganciare venga preso dal PersistentVolumeClaim in cui specifico il nome (il mount successivo č giŕ stato spiegato piů volte). Ma cosa succede ora se inserisco in Minikube questo template?
# kubectl apply -f nginx.yaml persistentvolumeclaim/my-pv-claim created pod/task-pv-pod created # kubectl get po NAME READY STATUS RESTARTS AGE task-pv-pod 0/1 Pending 0 12s # kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-pv-claim Pending 2m53s
E il pod rimane Pending cosě come il PersistentVolumeClaim (get pvc), perché effettivamente hanno fatto la richiesta dello storage, ma nessuno gli ha assegnato quanto richiesto. Per accertarci di questo:
# kubectl describe po task-pv-pod ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 57s (x3 over 117s) default-scheduler error while running "VolumeBinding" filter plugin for pod "task-pv-pod": pod has unbound immediate PersistentVolumeClaims
Per creare lo storage posso scrivere per Minikube:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0001
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 1Mi
hostPath:
path: /data/pv0001/Che creerŕ uno storage con l'accessMode e la capacity richiesta dal claim visto prima:
# kubectl apply -f vol.yaml persistentvolume/pv0001 created # kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pv0001 1Mi RWO Retain Bound default/my-pv-claim 56s
Il persistent volume č stato creato e nella colonna STATUS e CLAIM si puň capire come č giŕ stato assegnato, infatti se controllo gli oggetti creati precedentemente:
# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-pv-claim Bound pv0001 1Mi RWO 6m29s # kubectl get po NAME READY STATUS RESTARTS AGE task-pv-pod 1/1 Running 0 6m35s
Anche il pod si č avviato con l'assegnazione del disco. In linea teorica come si presenta la situazione ora? Il developer, o chi per lui, puň creare tutti i template che vuole e i pod di suo interesse specificando i volume di suo interesse, dall'altro lato, chi amministra i server, puň mettere a disposizione vari tipi di storage giŕ pronti che Kubernetes assegnerŕ automaticamente ai pod richiedenti (ovviamente la richiesta e l'offerta deve essere compatibile). Anche se questo facilitava notevolmente il tutto si apriva un altro problema, cioč come prevedere il numero dei volume e la loro capacitŕ in un ambiente dove i pod sono centinaia se non migliaia? La creazione e la gestione degli stessi avrebbe gravato sull'amministratore del cluster. Cosě si č aperta un'altra possibile soluzione: la creazione automatica dei dischi richiesti con il PersistentVolumeClaim.
Nella definizione vista prima č presente una voce che č stata lasciata vuota appositamente, storageClassName:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: my-pv-claim
spec:
storageClassName: ""
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1MiDefinendo in questo attributo la class name, daremo il compito a lui di creare il disco per le nostre esigenze. Per sapere se nel nostro cluster Kubernetes č presente, basta scrivere (con Minikube attivo):
# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE fast (default) k8s.io/minikube-hostpath Delete Immediate false 5d15h standard (default) k8s.io/minikube-hostpath Delete Immediate false 7d23h
Con AWS:
# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE gp2 (default) kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 5m57s
Con Docker Desktop:
# kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE hostpath (default) docker.io/hostpath Delete Immediate false 31d
Per ora prendo in considerazione solo Minikube, dove sono presenti ben due classi: "fast" e "standard", entrambe sono un valore di default quindi č obbligatorio specificarne il nome nell'attributo storageClassName. Nel caso di AWS o Docker Desktop, dove č presente solo una voce, infatti, avrei potuto eliminare la riga per la definizione dello storageClassName:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: my-pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1MiE avrebbe funzionato perfettamente, mentre con Minikube ora devo scrivere:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: my-pv-claim
spec:
storageClassName: fast # o standard
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1MiCancellato quanto fatto finora ed eseguito nuovamente ora avrň:
# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-b122eb76-7f7d-470d-ad27-aefe1cfce48e 1Mi RWO Delete Bound default/my-pv-claim fast 16s # kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE my-pv-claim Bound pvc-b122eb76-7f7d-470d-ad27-aefe1cfce48e 1Mi RWO fast 18s # kubectl get po NAME READY STATUS RESTARTS AGE task-pv-pod 1/1 Running 0 21s
Ora senza dover creare appositamente lo storage, Minikube l'ha creato con le specifiche volute e assegnato al pod, problema risolto. Ed ora di ritornare al progetto iniziale dove tre istanze di MySql aspettano il proprio storage. L'implementazione della storage class č abbastanza semplice ora, prima uno sguardo alla sezione volumeMounts:
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
- name: secretvolume
readOnly: true
mountPath: "/etc/secret-volume"A parte la definizione dei path per la configurazione e per i secret (dove ho inserito le credenziali come ho spiegato nel post precedente), ho definito anche il mounthPath per i data, che č la directory dove MySql salverŕ i dati. In StatefulSet č presente la sezione volumeClaimTemplates:
volumeClaimTemplates:
- metadata:
name: data
spec:
#storageClassName: fast
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10GiIn questo caso, essendo l'esempio pubblicato su AWS, ho specificato che ho bisogno di uno storage di 10GB, ho commentato la riga della definizione dello storageClassName perché con AWS non serve - avrei potuto inserire la riga: storageClassName: gp2. Anzi, non inserire lo storageClassName, mi permette di trasferire il tutto in altri cloud senza modificare nulla nel codice. In ogni caso, per esigenze particolari, č possibile creare anche storage piů performanti per usi particolari, e questo ci obbliga a mettere mano al codice del template.
E' arrivato il momento di provare il tutto. Innanzitutto si deve creare il cluster EKS in AWS. Ci sono vari metodi, il piů semplice č direttamente dall'interfaccia web anche se poi si dovranno creare role a altro, e importare la configurazione per poter poi accedere da console con il comando kubectl. Dopo vari suggerimenti ho imparato che il metodo piů semplice č grazie al comando eksctl. Da terminale bash posso creare il tutto con l'unico comando:
eksctl create cluster --name test-cluster --version 1.18 --region eu-central-1 --nodegroup-name my-nodes --node-type t2.medium --nodes 3
In cui definisco il nome che avrŕ il cluster in AWS, la versione di Kubernetes che voglio utilizzare, in quale region (in questo caso per abitudine uso il Datacenter a Francoforte ma č disponibile anche a Milano), e infine quanti worker node voglio creare, quale tipo di macchine devono essere utilizzate e il nome del gruppo alla quale saranno assegnate. Tutto qua. Lanciato il comando dopo un tempo variabile tra i dieci e i quindici minuti, viene creato tutto:

Il comando eksctl dietro le quinte crea due template per Cloudfront che poi vengono eseguiti per la creazione di tutta l'infrastruttura. Questo permette, alla fine dei test, di poter cancellare il tutto con un solo comando. Inoltre questo comando crea la configurazione corretta in locale per il comando kubectl e ci permette si lavorare fin da subito con AWS:
... [?] kubectl command should work with "/home/az/.kube/config", try 'kubectl get nodes' ...
E' ora di lanciare in AWS quanto creato finora. Inizio con la ConfigMap, i secret e infine i service:
# kubectl apply -f mysql-configmap.yaml # kubectl apply -f mysql-secret.yaml # kubectl apply -f mysql-services.yaml
Ora creo le tre istanze di MySql:
# kubectl apply -f mysql-statefulset.yaml
Se tutto č andato bene ora si dovrebbero poter vedere i dischi creati automaticamente da AWS:
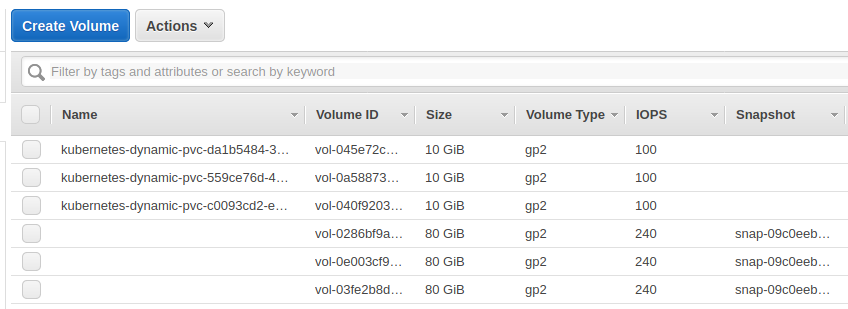
E controllo che ci siano tutti i pod per MySql in replica:
# kubectl get po NAME READY STATUS RESTARTS AGE mysql-0 2/2 Running 0 3m44s mysql-1 2/2 Running 0 2m45s mysql-2 2/2 Running 0 97s
E' il momento della web application. Creo un pod e un service per lui:
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
selector:
app: webapp
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: LoadBalancer
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
labels:
app: webapp
spec:
replicas: 3
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: webapp
image: sbraer/mysqlidentity:v1
imagePullPolicy: IfNotPresent
env:
- name: MySqlServerName
value: mysql-0.mysql
- name: MySqlDatabaseName
value: Test1
- name: MySqlUsername
value: a1
- name: MySqlPassword
value: b1
- name: MySqlServerNameReader
value: mysql-read
- name: MySqlDatabaseNameReader
value: Test1
- name: MySqlUsernameReader
value: a1
- name: MySqlPasswordReader
value: b1Ora controllo che tutto sia stato creato correttamente:
#kubectl get po NAME READY STATUS RESTARTS AGE mysql-0 2/2 Running 0 7m10s mysql-1 2/2 Running 0 6m11s mysql-2 2/2 Running 0 5m3s webapp-745bdf47b9-2jhpp 1/1 Running 0 67s webapp-745bdf47b9-2r5h7 1/1 Running 0 83s webapp-745bdf47b9-vt8fr 1/1 Running 0 75s
Ho creato un LoadBalancer tra i service:
#kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 19m mysql ClusterIP None <none> 3306/TCP 8m24s mysql-read ClusterIP 10.100.97.86 <none> 3306/TCP 8m24s webapp LoadBalancer 10.100.84.34 aa2e3011816b74f4d83c178407ab3373-667334319.eu-central-1.elb.amazonaws.com 80:32305/TCP 2m19s
Il LoadBancler, nella colonna EXTERNAL-IP contiene un url. Richiamandolo nel browser:

AWS ha creato, grazie alla dichiarazione del service come LoadBalancer, un suo Load Balancer ed ha reso immediatamente pubblica la web application:

La cosa č positiva, perché nella configurazione di Kubernetes mi č sufficiente inserire un LoadBalancer come service perché venga creato un Application Load Balancer in AWS e i miei pod siano esposti su Internet. Ma c'č il rovescio della medaglia: oltre che č uno spreco creare un Applicatoin Load Balancer per ogni servizio, ogni singola istanza ha un costo. Per fortuna c'č una soluzione alternativa conosciuta e utilizzata, che risolve questo problema collegando un singolo Load Balancer di AWS a uno o piů service in Kubernetes. Inizio cancellando la webapp e il suo servizio:
kubectl delete -f webapp.yaml
Che cancellerŕ anche il LoadBalancer di AWS. Quindi modifico il service della web app:
apiVersion: v1
kind: Service
metadata:
name: webapp
spec:
selector:
app: webapp
ports:
- protocol: TCP
port: 5000
targetPort: 5000Ora č diventato un servizio interno:
#kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 28m mysql ClusterIP None <none> 3306/TCP 17m mysql-read ClusterIP 10.100.97.86 <none> 3306/TCP 17m webapp ClusterIP 10.100.61.159 <none> 5000/TCP 3s
Per pubblicare la web application su Internet la soluzione č utilizzare NGINX Ingress Controller (sono presenti altri progetti analoghi ma specifi per AWS, Azure e altri). Disponibile per i maggiori cloud (altrimenti si puň usare HELM), permette di creare un'unica porta tra il L'Application Load Balancer del cloud (nel mio caso AWS) e il cluster in Kubernetes. La sua installazione č semplice:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.41.2/deploy/static/provider/aws/deploy.yaml
Guardando in AWS ora troverň un Application Load Balancer. E ora con un ingress service collegherň qualsiasi servizio a questa istanza di nginx :
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: api-ingresse-test
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: a5776edeb49d94da09accdec22690dd8-76a165cfec2847c5.elb.eu-central-1.amazonaws.com #dns name preso da AWS-> Load balancer
http:
paths:
- backend:
serviceName: webapp
servicePort: 5000
path: /In host ho messo il DNS del LoadBalacer, e nella sezione http il service name (webapp) e la porta a cui risponde (5000).
#kubectl get ingress NAME CLASS HOSTS ADDRESS PORTS AGE api-ingresse-test <none> a5776edeb49d94da09accdec22690dd8-76a165cfec2847c5.elb.eu-central-1.amazonaws.com 80 6s
E controllo che la pagina web risponda:

Quando si definisce un Ingress č importante inserire l'host il nome a cui risponde l'nginx ingress controller; nel mio esempio ho inserito il DNS Name del load balancer, ma nel mondo reale sarŕ necessario far puntare il nome del dominio all'IP del load balancer. Ipotizzando di avere il dominio www.site.com e avendolo configurato tutto correttamente, avrei dovuto inserire il nome del dominio nell'attributo host visto qui sopra. Ma se volessi utilizzare tale dominio perché rispondano piů web application?
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: api-ingresse-test
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: www.site.com
http:
paths:
- backend:
serviceName: webapp
servicePort: 5000
path: /
- backend:
serviceName: webapp2
servicePort: 5001
path: /otherCon l'url www.site.com sarŕ avviata ancora la mia webapp, con l'url www.site.com/other sarŕ richiamata la webapp2. Se webapp2 fosse una web application in asp net core si avrŕ una sorpresa una volta eseguita questa configurazione. Richiamando l'url www.site.com/other sarŕ visualizzata una pagina bianca. Questo problema č noto e la soluzione la si puň trovare qui (nella mia web application ho inserito il supporto del cambio del PathBase grazie alla variabile d'ambiente API_PATH_BASE).
Inoltre, avendo configurato i nomi di dominio www.example.com e qa.example.com in modo che puntino all'ip nel mio load balancer, posso scrivere:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: api-ingresse-test
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: www.site.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: webapp
port:
number: 5000
- host: qa.site.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: qawebapp
port:
number: 5000In modo da avere la versione di produzione al dominio www.site.com, mentre la versione in test sarŕ visibile in qa.site.com.
Sono quasi alla fine. In alcuni post dedicati a Docker Swarm avevo dato enfasi alla possibilitŕ di assegnare alcuni container docker a determinate macchine. L'esempio che facevo era dedicato alle diverse tipologie di macchine che potevano fare parte del cluster per potenza di cpu, memoria o capacitŕ e velocitŕ dei dischi. Anche nel caso di cloud (AWS o altri) č possibile decidere la tipologia di macchine che potrebbero essere utilizzate per determinati processi e non per scopi poco importanti. Nel mio esempio ho creato tre istanze di MySql, e se pubblicato come visto finora potrebbe capitare che due istanze vengano assegnate alla stessa macchina, l'altra istanza assegnata ad una seconda macchina mentre la terza lasciata vuota. L'ideale, anche per la sicurezza per malfunzionamenti, riavvii o altro, sarebbe quella di avere un'istanza di MySql per ogni macchina.
Con Docker Swarm si poteva assegnare una label ad una macchina, e nalla fase di avvio di un container in Docker si poteva decidere di assegnarlo proprio a lei. Anche con Kubernetes č possibile l'assegnazione di pod a determinate macchine e altre interessanti funzioni che combinate permettono l'assegnazione di pod in modo puntuale. A livello di singole macchine possiamo avere il node affinity che avvisa Kubernetes che determinati pod possono essere lě avviati; al contrario, i taint, vietano a certi pod di essere eseguiti su quella macchina. Personalmente trovo i taint molto interessanti e utili, perché permettono di assegnare dei pod a determinate macchine (che tollerano questi taint) e proibiscono tutti gli altri. Questo permette di creare ristretti cluster di macchine assegnate a determinati compiti. Nell'esempio del replica di tre macchine per MySql posso creare tre macchine quindi aggiungo il taint in questo modo:
kubectl taint node nome_macchina_1 node-type=database:NoSchedule kubectl taint node nome_macchina_2 node-type=database:NoSchedule kubectl taint node nome_macchina_3 node-type=database:NoSchedule
Nelle tre macchine ho inserito il custom taint con la key node-type e il valore database, NoSchedule specifica che queste macchine NON possono accettare la schedulazione di nuovi pod. Se per la key e il suo valore posso inserire quello che voglio, il terzo valore, definito nella documentazione come effect, accetta tre valori:
- NoSchedule, dal momento dell'inserimento di questo custom taint nessun altro pod, se non specificato come si vedrŕ dopo, non potrŕ essere su questa macchina (quelli giŕ presenti non saranno toccati).
- PreferNoSchedule, č la versione soft di NoSchedule: come sopra ma se non ci sono altre macchine che possono accettare i nuovi pod, viene permessa la loro esecuzione.
- NoExecute: č la versione piů cattiva: nessun pod puň girare su questo server, anche quelli che sono giŕ presenti.
Se volessi controllare i taint presenti su una macchina, č sufficiente controllare l'output di questo comando:
#kubectl describe node nomemacchina ... CreationTimestamp: Tue, 27 Oct 2020 13:37:20 +0100 Taints: node-type=database:NoSchedule Unschedulable: false ...
Ora che le tre macchine qui sopra sono tutte dedicate alle tre istanze di MySql, si deve specificare nella definizione dei pod la toleration che permetterŕ ai pod di poter essere avviati:
...
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
tolerations:
- key: node-type
operator: Equal
value: database
effect: NoSchedule
...In tolerations specifico che i pod potranno girare sulle macchine dove ho specificato il custom taint con quella key, value e effect - ma questo non preclude che quel pod non possa essere avviato su altre macchine e non preclude il problema principale dell'avvio di due istanze di MySql sulla stessa macchina. Per evitare questo č presente l'affinity per i pod: PodAffinity con il quale si puň specificare che un pod debba girare sulla stessa macchina dove č presente un altro specifico pod, ed č presente il PodAntiAffinity che funziona al contrario del precedente: si puň evitare che un pod possa girare sulla stessa macchina dov'č presente un determinato pod. E' quello che fa per il mio caso. Ecco la configurazione che mi permette di avviare le tre istanze di MySql sulle tre macchine scelte e ognuna su una singola macchina:
...
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
tolerations:
- key: node-type
operator: Equal
value: production
effect: NoSchedule
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
app: mysql
...In affinity ho specificato il podAntiAffinity, e con requiredDuringSchedulingIgnoredDuringExecution (che si scrive sbagliato quattro volte su cinque) specifico che il pod puň essere avviato (required...) se quella macchina (topologyKey: kubernetes.io/hostname) non ha un pod con la label app:mysql. In topologyKey posso specificare altre variabili presente sulla macchina, come la region, in modo che quel pod non debba essere avviato nella stessa region, oppure si possono specificare determinate macchine per armadi, stanze o piani del datacenter. Alternativo a requiredDuringSchedulingIgnoredDuringExecution, in cui specifico che quella regola dev'essere rispettata, c'č preferredDuringSchedulingIgnoredDuringExecution, che rende opzionale la regola.
Come scritto sopra preferisco nella mia limitata esperienza l'uso delle custom taints su tutte le macchine. In questo modo in un cluster formato da molte macchine nessun pod puň avviarsi se non specificando la toleration. Altra alternativa č specificare la node affinity dove si specifica su quali macchine i pod devono essere installati, e in questo caso si possono specificare piů regole dando ad ognuna un peso, in modo che Kubernetes scelga l'assegnazione valutando innanzitutto la possibilitŕ dell'avvio di quei pod, e quindi il peso di tale regola. Le possibilitŕ che offre Kubernetes per questo scopo sono innumerevoli, e meriterebbero un lungo post dedicato, ma non ne ho voglia e poi la documentazione a riguardo e chiara (se l'ho capita pure io...), si puň partire da qui.
E ora di chiudere tutto. Quello che ho attivato con eksctl puň essere distrutto con esso:
eksctl delete cluster --name test-cluster
Dopo qualche minuto tutte le risorse create in AWS saranno distrutte. Tutte tranne i dischi creati automaticamente grazie alla storage class, in questo modo vengono salvaguardati eventuali dati inseriti - se non piů necessari sarŕ necessario cancellarli manualmente. Per controllare:
#kubectl get pvc #kubectl get pv
E si puň decidere di cancellarle (questo č comodo anche per ripristinare una situazione precedente che potrebbe bloccare la cancellazione e la creazione di pod che utilizzano quegli storage):
#kubectl delete pvc --all #kubectl delete pv --all
Ci sono molte altre feature interessanti con l'utilizzo del cloud, come la possibilitŕ dell'autoscaling orizzontale dei worker node: in caso di aumento di richieste e di numero dei pod che i worker node non possono piů avviare, AWS puň avviare altre macchine, cosě come le puň eliminare in caso di consumo inferiore di risorse - ma questo obbligherebbe l'approfondimento dell'uso delle risorse dei pod, con la configurazione delle richieste minime e massime di memoria e cpu, e cosě via. Inoltre, interessante anche il supporto all'autoscaling nativo di Kubernetes, ma č roba che allungherebbe questo post ulteriormente e non era lo scopo iniziale. Forse in futuro? No. Inoltre AWS permette l'uso di Kubernetes in modalitŕ Fargate: senza nodi worker ma istanziando i pod di volta in volta a seconda delle esigenze.
Prima di chiudere qualche parola su HELM che č un package manager di Kubernetes: qui si possono trovare giŕ pronti e configurati parecchi software anche complessi da configurare. Per esempio, l'esempio qui mostrato con l'avvio in replica di tre istanze di MySql č presente e attivabile con una riga da console con il comando HELM. Perché io non l'ho fatto? Perché io ero curioso di verificare e personalizzare alcuni punti di mio interesse. Quanto avevo fatto il post precedente per MongoDb in replicaset? Anche quello script č giŕ presente e pronto all'uso.
Infine due parole sull'utilizzo del cloud per testare Kubernetes. Come scritto all'inizio č meglio utilizzarlo solo per progetti reali o di una certa complessitŕ con oggetti non disponibili in locale, anche perché il suo utilizzo non č economico visto che qualsiasi risorsa in AWS dev'essere pagata; personalmente per altri miei progetti personali da qualche tempo affianco Minikube/Aws ad un altro cloud: Linode. Innanzitutto l'avvio di un cluster Kubernetes non č a pagamento orario come AWS (si pagano solo l'uso dei worker node), e soprattutto il suo avvio avviene in pochissimi minuti contro i dieci/quindici minuti di AWS, e lo spegnimento č quasi immediato mentre con AWS ci vogliono circa cinque minuti. Mancano feature come l'autoscaling o la modalitŕ serverless di AWS Fargate, ma quelle sono esigenze particolari. Consiglio di dargli un'occhiata. Fine.
PS nel link del progetto della web application č presente una directory di nome Kubernetes dove sono presenti i file yaml usati.

Per inserire un commento, devi avere un account.
Fai il login e torna a questa pagina, oppure registrati alla nostra community.
- Kubernetes e MongoDb Replica Set, il 12 febbraio 2020 alle 22:00
- Docker Stack e MongoDb Replica Set, il 7 dicembre 2019 alle 19:57